
23 result's for “perplexity ai”
-
Cloudflare just entered the AI monetization chat.
One of the core tensions with SEO and now AEO (AI Engine Optimization) is access. If you block bots from crawling your content, you lose visibility. But if you don’t block them, your content gets scraped, summarized, and served elsewhere without credit, clicks, or revenue.
For publishers like Reddit, recipe sites, and newsrooms, that’s not just a tech issue, it’s an existential one. Tools like Perplexity and ChatGPT summarize entire pages, cutting publishers out of the traffic (and ad revenue) loop.
Now Cloudflare’s testing a new play: charge the bots. Their private beta lets sites meter and monetize how AI tools crawl their content. It’s early, but it signals a bigger shift. The market’s looking for a middle ground between “open” and “owned.” And the real question is—who gets paid when AI learns from your work?
-
AI Workshop: Are You Ready for Answer Engine Optimization?
How to Make Your Content Discoverable by AI, Not Just Google
Session Description:
This interactive, 90-minute session is designed for marketers, content creators, and business professionals who want to future-proof their visibility in a world where generative AI—not Google—is answering the questions.
As tools like ChatGPT, Perplexity, and Claude become the first stop for users seeking answers, the way content is found, cited, and used has fundamentally changed. Traditional SEO is no longer enough. In this session, you’ll learn how answer engines work, what AI models prioritize when retrieving and generating content, and how to structure your website, documents, and knowledge bases to stay relevant in an AI-powered ecosystem.
We’ll walk through the shift from search to synthesis, show you how AI “reads” your content, and help you take the first steps in adopting Answer Engine Optimization (AEO) for your business or team.
Download Files or Access ResourcesExcellent information in a simple format.
It was the perfect beginners look at AI.
It was great insight into the use of AI from a different perspective than simply ask and answer a question.
A masterclass by Jason Perry on customization of ChatGPT. The forward-thinking strategies discussed have opened new avenues for me to explore.
The workshop was very informative.
Very much enjoyed the presentation! Interesting to see the variety of AI products available.
What You’ll Learn:
- What AEO is and how it’s different from traditional SEO
- Why generative AI is reducing search traffic—and what that means for your content
- How AI models retrieve and synthesize answers using trained data or real-time tools
- The impact of robots.txt, training permissions, and data visibility on your brand
- What Claude, Perplexity, and ChatGPT actually prioritize when citing content
- How to structure your website, documents, and FAQs for AI comprehension
- Why now is the time to invest in AI-optimized content—and how to start
Instructor

Jason Michael Perry
Founder & Chief AI Officer, PerryLabsJason Michael Perry brings over 20 years of experience at the intersection of technology, innovation, and strategy. As the Founder and Chief AI Officer of PerryLabs, he helps teams and organizations confidently integrate AI into their everyday work without the fluff or overwhelm.
He’s the author of The AI Evolution and writes the weekly newsletter Thoughts on Tech & Things, where he breaks down complex tech topics with clarity, wit, and a practical lens.
Jason has advised Fortune 500s, government agencies, and nonprofits, and has taught 1,000+ professionals how to use AI to boost productivity, improve communication, and streamline decision-making.
He also serves as:
- Entrepreneur in Residence at the University of Baltimore
- Senior Advisor at the World Trade Center Institute
- Board Member at the Baltimore Symphony Orchestra
- Creator of AI in A Minor, an award-winning AI/music collaboration with AWS
Whether he’s speaking on stage or guiding a hands-on workshop, Jason is known for making AI accessible, engaging, and immediately useful.
-
AI Is Eating the Internet, And Your Traffic
I know I’ve said this before, but it’s worth repeating: If your business relies heavily on Google search traffic, you need to prepare for a reality where that hose turns from a stream to a drip.
Search traffic is declining. AI is accelerating the shift. And more evidence keeps piling up.
Cloudflare, a company best known for keeping websites fast, secure, and online, also offers tools to block AI bots from scraping public web content. If you’ve ever hit a “verify you’re not a robot” check before reading an article, that’s Cloudflare or similar services doing their job to protect publishers’ content from being quietly hoovered up.
In a recent interview, Cloudflare’s CEO laid it out clearly: publisher traffic is down hard. Worse, the new wave of AI search, Perplexity, ChatGPT, Gemini, doesn’t send readers back to your site the way old-school Google blue links did.
Some say this signals the death of the open web. Maybe they’re right.
But I think we’re witnessing a transition.
The open web, once the front door to everything, is fading. Today, most people experience the internet through closed ecosystems: YouTube, Amazon, TikTok, Instagram, Reddit, Facebook, Twitter. Each of these platforms has sticky sandboxes designed to keep users (and their content) locked inside.
If you’re not building brand gravity outside of SEO, if your whole model depends on inbound clicks from Google, things are going to get difficult quickly.
-
A Week of Dueling AI Keynotes
Microsoft Build. Google I/O. One week, two keynotes, and a surprise plot twist from OpenAI. I flew to Seattle for Build, but the week quickly became about something bigger than just tool demos; it was a moment that clarified how fast the landscape is moving and how much is on the line.
For Microsoft, the mood behind the scenes is… complicated. Their internal AI division hasn’t had the impact some expected. And the OpenAI partnership—the crown jewel of their AI strategy—feels increasingly uneasy. OpenAI has gone from sidekick to wildcard. Faster releases, bolder moves, and a growing sense that Microsoft is no longer in the driver’s seat.
Google has its own tension. It still prints money through ads, but it just lost two major antitrust cases and is deep in the remedies stage, which could change the company forever. Meanwhile, the company is trying to reinvent itself around AI, even at its core business model (search + ads) starts to look shaky in a world where answers come from chat, not clicks.
Let’s start with Microsoft
The Build keynote focused squarely on developers and, more specifically, how AI can make them exponentially more powerful. This idea—AI as a multiplier for small, agile teams—is core to how I think about Vibe Teams. It’s not about replacing engineers. It’s about amplifying them. And this year, Microsoft leaned in hard.
One of the most exciting announcements was GitHub Copilot Agents. If you’ve played with tools like Claude Code or Lovable, you know how quickly AI is changing the way we write software. We’re moving from line-by-line coding to spec-driven development, where you define what the system should do, and agentic AI figures out how.
Copilot Agents takes that further. You can now assign an issue or bug ticket in GitHub to an AI agent. That agent will create a new branch, tackle the task, and submit a pull request when it’s done. You review the PR, suggest edits if needed, and decide whether to merge. No risk to your main codebase. No rogue commits. Just a smart collaborator who knows the rules of the repo.
This isn’t just task automation—it’s the blueprint for how teams might work moving forward. Imagine a lead engineer writing specs and reviewing pull requests—not typing out every line of code but conducting an orchestra of agentic contributors. These agents aren’t sidekicks. They’re teammates. And they don’t need coffee breaks.
Sam Altman joined Satya Nadella remotely – another telling sign that their relationship is collaborative but increasingly arms-length. Satya reiterated Microsoft’s long view, and Sam echoed something I’ve said for a while now: “Today’s AI is the worst AI you’ll ever use.” That’s both a promise and a warning.
The next wave of announcements went deeper into the Microsoft stack. Copilot is being deeply embedded into Microsoft 365, supported by a new set of Copilot APIs and an Agent Toolkit. The goal? Create a marketplace of plug-and-play tools that expand what Copilot Studio agents can access. It’s not just about making Teams smarter – it’s about turning every Microsoft app into an environment agents can operate inside and build upon.
Microsoft also announced Copilot Tuning inside Copilot Studio – a major upgrade that lets companies bring in their own data, refine agent behavior, and customize AI tools for specific use cases. But the catch? These benefits are mostly for companies that are all-in on Microsoft. If your team uses Google Workspace or a bunch of best-in-breed tools, the ecosystem friction shows.
Azure AI Studio is also broadening its model support. While OpenAI remains the centerpiece, Microsoft is hedging its bets. They’re now adding support for LLaMA, HuggingFace, GrokX, and more. Azure is being positioned as the neutral ground—a place where you can bring your model and plug it into the Microsoft stack.
Now for the real standout: MCP.
The Model Context Protocol—originally developed by Anthropic—is the breakout standard of the year. It’s like USB-C for AI. A simple, universal way for agents to talk to tools, APIs, and even hardware. Microsoft is embedding MCP into Windows itself, turning the OS into an agent-aware system. Any app that registers with the Windows MCP registry becomes discoverable. An agent can see what’s installed, what actions are possible, and trigger tasks, from launching a design in Figma to removing a background in Paint.
This is more than RPA 2.0. It’s infrastructure for agentic computing.
Microsoft also showed how this works with local development. With tools like Ollama and Windows Foundry, you can run local models, expose them to actions using MCP, and allow agents to reason in real-time. It’s a huge shift—one that positions Windows as an ideal foundation for building agentic applications for business.
The implication is clear: Microsoft wants to be the default environment for agent-enabled workflows. Not by owning every model, but by owning the operating system they live inside.
Build 2025 made one thing obvious: vibe coding is here to stay. And Microsoft is betting on developers, not just to keep pace with AI, but to define what working with AI looks like next.
Now Google
Where Build was developer-focused, Google I/O spoke to many audiences, sometimes pitching directly to end-users and sometimes to developers. Google I/O pushed to give a peek at what an AI-powered future could look like inside the Google ecosystem. It was a broader, flashier stage, but still packed with signals about where they’re headed.
The show opened with cinematic flair: a vignette generated entirely by Flow, the new AI-powered video tool built on top of Veo 3. But this wasn’t just a demo of visual generation. Flow pairs Veo 3’s video modeling with native audio capabilities, meaning it can generate voiceovers, sound effects, and ambient noise, all with AI. And more importantly, it understands film language. Want a dolly zoom? A smash cut? A wide establishing shot with emotional music? If you can say it, Flow can probably generate it.
But Google’s bigger focus was context and utility.
Gemini 2.5 was the headliner, a major upgrade to Google’s flagship model, now positioned as their most advanced to date. This version is multimodal, supports longer context windows, and powers the majority of what was shown across demos and product launches. Google made it clear: Gemini 2.5 isn’t just powering experiments—it’s now the model behind Gmail, Docs, Calendar, Drive, and Android.
Gemini 2.5 and the new Google AI Studio offer a powerful development stack that rivals GitHub Copilot and Lovable. Developers can use prompts, code, and multi-modal inputs to build apps, with native support for MCP, enabling seamless interactions with third-party tools and services. This makes AI Studio a serious contender for building real-world, agentic software inside the Google ecosystem.
Google confirmed full MCP support in the Gemini SDK, aligning with Microsoft’s adoption and accelerating momentum behind the protocol. With both tech giants backing it, MCP is well on its way to becoming the USB-C of the agentic era.
And then there’s search.
Google is quietly testing an AI-first search experience that looks a lot like Perplexity – summarized answers, contextual follow-ups, and real-time data. But it’s not the default yet. That hesitation is telling: Google still makes most of its revenue from traditional search-based ads. They’re dipping their toes into disruption while trying not to tip the boat. That said, their advantage—access to deep, real-time data from Maps, Shopping, Flights, and more—is hard to match.
Project Astra offered one of the most compelling demos of the week. It’s Google’s vision for what an AI assistant can truly become – voice-native, video-aware, memory-enabled. In the clip, an agent helps someone repair a bike, look up receipts in Gmail, make phone calls unassisted to check inventory at a store, reads instructions from PDFs, and even pauses naturally when interrupted. Was it real? Hard to say. But Google claims the same underlying tech will power upcoming features in Android and Gemini apps. Their goal is to graduate features from Astra as they evolve from showcase to shippable, moving beyond demos into the day-to-day.
Gemini Robotics hinted at what’s next, training AI to understand physical environments, manipulate objects, and act in the real world. It’s early, but it’s a step toward embodied robotic agents.
And then came Google’s XR glasses.
Not just the long-rumored VR headset with Samsung, but a surprise reveal: lightweight glasses built with Warby Parker. These aren’t just a reboot of Google Glass. They feature a heads-up display, live translation, and deep Gemini integration. That display can able to silently serve up directions, messages, or contextual cues, pushing them beyond Meta’s Ray-Bans, which remain audio-only. These are ambient, spatial, and persistent. You wear them, and the assistant moves with you.
Between Apple’s Vision Pro, Meta’s Orion prototypes, and now Google XR, one thing is clear: we’re heading into a post-keyboard world. The next interface isn’t a screen, it’s an environment. And Google’s betting that Gemini, which they say now leads the field in model performance, will be the AI to power it all.
And XR glasses seem like a perfect time for Sam Altman to steal the show…
OpenAI and IO sitting in a tree…
Just as Microsoft and Google finished their keynotes, Sam Altman and Jony Ive dropped the week’s final curveball: OpenAI has acquired Ive’s AI hardware-focused startup, IO, for a reported $6.5 billion.
There were no specs, no images, and no product name. Just a vision. Altman said he took home a prototype, and it was enough to convince him this was the next step. ‘I’ve described the device as something designed to “fix the faults of the iPhone,” less screen time, more ambient interaction. Rumors suggest it’s screenless, portable, and part of a family of devices built around voice, presence, and smart coordination.
In a week filled with agents, protocols, and assistant upgrades, the IO announcement begs the question:
What is the future of computing? Are Apple, Google, Meta, and so many other companies right to bet on glasses?
And if it’s not glasses, not headsets, not wearables, we’ve already seen—but something entirely new. What might the new interface to computing look like?
And with Ive on board, design won’t be an afterthought. This won’t be a dev kit in a clamshell. It’ll be beautiful. Personal. Probably weird in all the right ways.
So where does that leave us?
AI isn’t just getting smarter—it’s getting physical.
Agents are learning to talk to software through MCP. Assistants are learning your context across calendars, emails, and docs. Models are learning to see and act in the world around them. And now hardware is joining the party.
We’re entering an era where the tools won’t just be on your desktop—they’ll surround you. Support you. Sometimes, speak before you do. That’s exciting. It’s also unsettling. Because as much as this future feels inevitable, it’s still up for grabs.
The question isn’t whether agentic AI is coming. It’s who you’ll trust to build the agent that stands beside you.
Next up: WWDC on June 10. Apple has some catching up to do. And then re:Invent later this year.
-
Issue #78: What’s Really Holding Back Your AI Strategy
Howdy 👋🏾.
Reality and possibility couldn’t be more different. Every week, I hear it:
- “Our AI chatbot sucks.”
- “Customers hate it.”
- “Employees will never use it.”
- “It can’t answer real questions.”
Of course it can’t.
There’s been a rush driven by board pressure and CEO mandates to do something with AI. Most of it? Garbage. And it’s no surprise. AI was never a magic pill for bad data, ancient infrastructure, or a decade of ignored technical debt. Slapping a chatbot on top of a mess doesn’t solve the mess.
The tide is turning. Users are frustrated, execs are disappointed, and the teams behind these deployments are left drained and wondering where it went wrong. Because AI is not the product. Readiness is. If you haven’t done the work integrating systems, cleaning up data, and training your people, it’s not just that AI will underdeliver. It might actively make things worse.
IBM’s latest study said it best:
- Only 25% of AI projects have delivered the ROI they promised
- Just 16% of companies have managed to scale AI across their organization
- Still, 61% of CEOs are moving full speed ahead — even though 64% admit they don’t fully understand what they’re investing in
This happens when FOMO (fear of missing out) replaces actual strategy. So let’s talk about what I’ve been building:
📕 My new book, The AI Evolution, is available for preorder.
I handed out early first-edition copies at Philly Tech Week, but now it’s available to order. You can grab a first edition directly from my site today. It hits Amazon and other retailers by June 12. Preorder here.
📣 PerryLabs is now live.
PerryLabs is a lab and a studio, built with AI at its core. We help people use AI strategically, creatively, and responsibly. It’s where experiments become products, and ideas drive real impact. Follow us on LinkedIn and visit our website to learn more.
📌 The $25K AI Accelerator.
This is for businesses ready to move fast and get real. Not just about tools, but it’s about readiness from data and infrastructure to team culture. We’ll help you design an actual AI strategy that works.
I talk to the people who work for you. They’re trying. They’re exploring tools. They’re making things happen on their own. But the truth is, they don’t always know what they don’t know.
If your organization hasn’t rolled out AI training, if AI governance isn’t on the roadmap, if you treat ChatGPT like a toy instead of a tool, let’s be honest… you’re not ready. AI training should be just as standard as phishing training.
I always say, today’s AI is the worst AI you’ll ever use. We’re in the AOL days of AI. It’s slow. It’s misunderstood. But this is the window. Today is where you build something that couldn’t exist before. Today is where you rethink what was, and imagine what’s next.
If that sounds like your kind of work, grab the book. Also, be sure to leave a review!
– jason
Bye SEO, Hello AEO

SEO isn’t dead, but the game is changing. As users turn to tools like ChatGPT and Perplexity instead of Google, the future lies in Answer Engine Optimization (AEO). It’s no longer about keywords, it’s about visibility in AI-generated answers. If your content isn’t being picked up by these tools, you’re invisible. I’m breaking down the signs of change, what it means for your business, and how to start adapting now.
The Best in Tech This Week
🔍 Google puts AI front and center on Search homepage – Google’s business is facing fundamental pressure. It’s easy to forget, with products like Gmail and Google Docs, that Google is primarily an advertising company, and Search is the crown jewel. It’s going to be interesting to watch them edge closer to AI while finding ways to protect that ad revenue.
⚖️ Republicans push federal ban on state AI regulation – In The AI Evolution, I talked about how state-by-state regulation was inevitable in the absence of federal rules. But I didn’t see this coming. A 10-year ban on state-level AI laws?
🤖 Amazon offers a peek at new human jobs in an AI-bot world – One thing often forgotten in the AI race: its impact on robotics. The investment here has been building for years. If I’m placing bets, vocational robotics is a smart one.
🎤 The AI Roadshow: Workshops, Talks & Beyond
May 19-22, 2025 – Microsoft Build
June 3, 2025 – University of Baltimore AI Summit
June 5, 2025 – AI Advantage: Building, Integrating & Scaling AI for your Business
June 24, 2025 – WTCI AGILE: Building Earth’s Future From Space
🔬 Inside the Lab: What’s new at PerryLabs
If you’re thinking about AI, it’s time to make it real. The PerryLabs AI Accelerator is a fast, focused 2–4 week engagement built to take you from idea to impact, no fluff, just results.
We’ll help you pinpoint where AI can drive the most value, mapping your systems, analyzing your data, and targeting the processes primed for automation.
✅ Fixed-fee, fast-track (starts at $25K)
✅ Includes stakeholder interviews, process deep dives & data review
✅ Perfect for ops, product, finance, and strategy leaders ready to moveLet’s accelerate: perrylabs.io | contact@perrylabs.io
P.S. Ants Love Sonos Play: 1
I just got back from a round trip to move my daughter out of her dorm, which meant a full catch-up on my podcast backlog. One that’s still rattling around in my head: the Sonos Play:1 is perfectly designed for a certain kind of ant. So much so that entire Reddit threads and forums are filled with people wondering why ants have colonized their speakers. Wild. Worth the listen:
-
Issue #74: AI, Jobs, and the Resume Wars
Howdy👋🏾. The Eagles demolished the Chiefs in the Super Bowl, and we got our first-ever OpenAI Super Bowl ad. I’m sure it wasn’t cheap, but what stood out to me most was how they’ve turned a simple black circle into a recognizable marker of their brand and identity.
I remember seeing in a recent OpenAI AMA that they consider this circle their mascot, which honestly makes a lot of sense—if any company should have an amorphous, ever-evolving symbol, it’s an AI company. If you missed the spot, here it is:
But OpenAI wasn’t the only AI company making waves. Perplexity skipped the $8 million+ Super Bowl ad spend and instead posted a single tweet (or is it an X now?). Their offer? Install the app, ask five questions, and one person wins $1 million.

It turns out that dangling a million-dollar prize works—Perplexity saw a 50% increase in app installs from this one post alone.
Of course, Google wasn’t about to sit this one out. Their ad took a more sentimental approach, celebrating fatherhood while showcasing how AI tools can assist in everyday life.
-jason
Writing an AI-Optimized Resume

Google’s Super Bowl ad painted a heartwarming picture of how AI can assist in job preparation, showing a father using Google Gemini’s voice tools to get ready for an interview. But beyond the feel-good narrative, this ad is a perfect lead-in to a much bigger conversation—one that explores how AI is both helping and hurting the job search market.
As layoffs continue across tech and beyond, AI-powered hiring tools are becoming both a lifeline and a barrier for job seekers. Applicant Tracking Systems (ATS) and AI-driven resume filters can make or break a candidate’s chances of landing an interview. In this deep dive, I explore how these tools work, what job seekers can do to optimize their resumes for AI screening, and whether AI is ultimately leveling the playing field—or making it harder than ever to get noticed.
🔗 The Best in Tech This Week
🤖 Elon Musk Wants to Buy OpenAI
Elon Musk has made an eye-popping $97 billion offer to buy OpenAI, reigniting his long-standing feud with the company he helped start. Given how things are going at X and Tesla’s sales slump in key markets, it’s unclear if this is a serious bid or a distraction. Meanwhile, Sam Altman wasted no time shutting it down, stating “OpenAI is not for sale.”📡 T-Mobile Expands Starlink Texting
T-Mobile is rolling out texting via Starlink satellites, allowing users in remote areas to send messages without traditional cell coverage. For now, it’s limited to text, but this could be a step toward global satellite-powered mobile service, disrupting traditional telecom networks.🇪🇺 The EU’s Stargate-Sized AI Bet
At the Paris AI Summit, European leaders pledged $200 billion in AI investment, hoping to compete with the US and China. With OpenAI’s Stargate project and China’s DeepSeek breakthroughs, the EU is trying to close the gap—but will this investment be enough to make Europe a real AI player?
🎤 The AI Roadshow: Workshops, Talks & Beyond
February 13, 2025 – MTC Technology Transformation Conference
February 18, 2025 – MD Student Venture Showcase
February 19, 2025 – AGILE: Empowering Global Disaster Response with Tech
🛠️ Podcasts, Pages, and Pixels: My Current Favorites
🎶 Suno: For music creation
Suno uses AI to help you compose music or create soundscapes. Whether you’re a musician or just experimenting, this tool makes music production accessible.
🔍 Perplexity: For AI search
An AI-powered search engine that provides quick, conversational answers with citations. Great for getting accurate information without sifting through endless search results.
P.S. Before you go…
I’ve featured Lazy Apply before, but what better time to bring it back than in a newsletter all about AI-powered job hunting? If companies are using AI to filter resumes at scale, maybe it’s time for job seekers to go on the offensive—and start automating applications just like companies automate screening. What could go wrong? Lazy Apply
-
Cloudflare Gives Creators Control Over AI Crawlers
Let’s face it—robots.txt wasn’t designed for the age of AI crawlers, which are ravenously consuming content across the web. For creators, it’s tough to swallow that their hard work is being used, often for free, to train AI models.
Cloudflare’s latest feature now allows websites to block AI models or bots with a simple click. If you’ve ever had to prove you’re human before accessing a site, that’s part of the toolkit Cloudflare is offering to help publishers stop the constant battle of restricting access.
While this might be a win for creators in the short term, there’s a lingering question: Will limiting access to AI crawlers make it harder for your content to be found in AI-powered answer engines like Perplexity AI? Only time will tell, but for now, the choice is yours.
-
Issue #56: AI and the Robots.txt Debate
Howdy 👋🏾. In the early days of search, websites needed a way to signal what, if any, of their content should be indexed by search engines. This served two purposes. First, some organizations might prefer that search engines like Google or Bing not index their content. Second, it allowed them to restrict specific types of pages from being indexed, such as membership-only content or other pages meant to be gated.
As a solution, a standard called the robots.txt file was introduced as a voluntary system that allows websites to signal their intentions to search engines. This has been the law of the land since 1994.
This file is getting new attention as a new question arises: what content on the open web should AI companies be allowed to use to train their models, and what content is off-limits? Many AI models have slurped content from the web, claiming it sits in the public domain, but have also released tools using the robots.txt file to allow websites to decide what content they would like to make available to these bots.
A few weeks ago, I shared the backlash Perplexity AI received for its AI-powered search engine, which some refer to as an answer engine, as it uses sourced content from the web to power responses but does not send traffic to the sources it pulls from. It was also discovered that Perplexity ran afoul of its own stated rules, pulling information into its answers from sites that explicitly asked it not to use their robots.txt file (Perplexity’s grand theft AI).
The response from Perplexity’s CEO made sense. “Perplexity is not ignoring the Robot Exclusions Protocol and then lying about it,” said Perplexity co-founder and CEO Aravind Srinivas in a phone interview. “I think there is a basic misunderstanding of how this works,” Srinivas said. “We don’t just rely on our own web crawlers; we rely on third-party web crawlers as well.”
In other words, indexing is not limited to a singular bot crawling the Internet. Different bots and third-party services used for their search make it difficult to easily point out that they are purposely not following the rules they stated.
Of course, Reddit, which has made it known that it plans to monetize the value of its community content fully, has gone a step further than robots.txt by implementing checks to identify bots and crawlers attempting to access its content and returning them a 404 (page not found) error. This ensures that this content is prohibited for those who ignore the voluntary pact of the robots.txt file (Reddit blocking search engine crawlers and AI bots).
What made me interested in this now is that OpenAI just released SearchGPT, its competitor to Perplexity AI. While I haven’t had the opportunity to try it myself, I have spent time reading how it works and noticed a pretty interesting bit about how it handles crawling for its search service (OpenAI Platform):

For the less technical readers, OpenAI has different bots that serve other uses, allowing publishers of content to grant more granular control to the various ways OpenAI may interact with openly crawled data:
- GPTBot: This bot is the one most are worried about. It actively consumes content it crawls and potentially uses to train OpenAI’s many generative models.
- ChatGPT-User: One of the features of the multimodal ChatGPT 4o is that a user can insert a web URL in a prompt, and ChatGPT can read that URL and use its contents to aid its response. This type of bot is used only for direct response to help the user, and the URL contents are not stored for search or training.
- OAI-SearchBot: This bot is for search. It indexes content to aid the search experience or to surface content, but the content crawled is not used to train models.
This all makes a ton of sense, and the more granular rule system gives publishers a ton of control in picking and choosing to what extent they would like to share their data with OpenAI. Perplexity appears to have one bot and one bot only, as stated in its documentation, but I could see it quickly following suit.
With the new complexities of AI and the diminishing line between AI-powered chatbots, search, and answering engines pushing us to Google Zero or zero-click traffic, one has to wonder if the voluntary robots.txt system is enough, or if Reddit’s heavier-handed approach of directly blocking bots is the best way. Who would have known that a small text file (The rise and fall of robots.txt) would be so important?
Now, my sponsors and my thoughts on tech & things:
🤝 This week’s newsletter issue is proudly sponsored by:

If you are looking to find qualified candidates, contact Baird Consulting.
🚫 Why Google Is No Longer Limiting Third-Party Cookies in Chrome – Google’s shift away from limiting third-party cookies in Chrome marks a significant change in the browser’s privacy approach. Explore the reasons behind this decision and its potential impact on web tracking and privacy. Read more>
🔍 OpenAI Just Released Search – OpenAI’s new search capabilities promise to revolutionize how we retrieve information. Dive into the features of this latest release and how it could reshape our interaction with AI. Read more >
🤖 Zuckerberg’s Thoughts on Open Source AI – Meta’s release of Llama 3.1, the largest open-source AI model with 405 billion parameters, sets a new standard in AI development. Discover the implications of this move and its potential impact on the AI ecosystem. Read more >
🍏 The First Taste of Apple Intelligence Is Here – Apple’s latest betas for iOS and iPadOS 18.1 introduce new Apple Intelligence features. Get a sneak peek at these innovations and what they mean for the future of Apple’s devices. Read more >
SearchGPT begs the question: what is search today? I initially viewed Perplexity AI as a search engine, but it’s quite different. It operates through a chat interface that enhances its responses with search results using a RAG-style approach. Is it search, or is the term “answer engine” or “AI chat” a better way to describe it?
Because these engines are coming from the perspective of AI and what should be used and allowed when training, or out of fear of giving AI too much access to our information, it also feels like OpenAI and Perplexity AI are getting away with limiting the sources they index for their search systems. Take this quote from OpenAI’s website:
“We are committed to a thriving ecosystem of publishers and creators. We hope to help users discover publisher sites and experiences, while bringing more choice to search. For decades, search has been a foundational way for publishers and creators to reach users. Now, we’re using AI to enhance this experience by highlighting high-quality content in a conversational interface with multiple opportunities for users to engage.”
With OpenAI and other AI companies working hard to license data from select publishers, in some ways this could lead to more limited sources powering these systems. Is Wired right to limit Perplexity AI? Would they ever consider doing the same to Google Search?
I don’t know the answers to these questions, but seeing how we figure them out will be interesting.
-jason
p.s. I’m a board member of the Baltimore Symphony Orchestra and a fan of jazz music, but alas, I do not play an instrument myself. I dream of playing the piano, maybe with a group of friends in a smoky dark jazz club in New Orleans, and until today I thought knowing how to play music was a prerequisite to releasing an album or performing live… but folks, H. Jon Benjamin, the voice of Archer and Bob from Bob’s Burgers, has shown me where there’s a will, there is indeed a way. Watch, and enjoy.
-
OpenAI Just Released Search!
I’m surprised it took so long. After all, OpenAI’s ChatGPT powers Microsoft’s Bing search, so in some ways, the company has been in the search game from nearly the start.
What’s interesting is that OpenAI’s approach is less like Bing and Google’s AI Overviews and more like Perplexity AI—my favorite new search tool in years. This is a good thing, changing our relationship with search from a list of results that may hold the answer to our questions, to actual responses that you can drill into with additional questions.
For access you need to join a waitlist, and I’m on it, so I can’t kick the tires just yet. OpenAI expects to integrate search into ChatGPT in the long term rather than maintaining them as separate products.
This means the competition in search is heating up for Google—and so far, their attempts to add AI to search have been lacking.
-
Issue #39: Exploring the World of Text-to-Video AI Models
Howdy 👋🏾, last month, Tyler Perry announced he was pulling back from his $800 million investment in a new film studio in Atlanta. This decision came after he laid eyes on OpenAI’s new AI diffusion model, Sora, which can create video from a text prompt. If you haven’t already, check out Sora’s videos; they’re amazing. Unfortunately, Sora is quite locked down, with access limited to a select audience, and plans for greater availability later this year (if you know someone, I would love access). However, it’s far from the only option, so this week, I thought I would give you a tour of some of the text-to-video AI models and how they work.
As a refresher, ChatGPT and most text-generative AI models are Large Language Models, which work as a very complex auto-suggest, guessing the next word or token in a phrase based on its training data. Most image models are diffusion models that diffuse or break up parts of an image bit by bit to understand its elements better. They then use that information to understand an image’s elements and use that data to generate new images or artwork. Stable Diffusion puts it right in the name, but Midjourney and DALL-E are also examples of diffusion models.
To date, most text-to-video models are limited to creating about 1 minute of video, as shown in Sora’s technical report comparing the differences between videos generated with different levels of compute power. Many of these models can also start with an image and transform it into a video or an animation, or extend an existing video to finish or complete it.
RunwayML
RunwayML’s new Gen-2 AI model allows you to create videos from a text prompt, extend an existing video, or use an existing image. I set up a free account that limits me to a handful of attempts and 4 seconds of generated video.
I asked RunwayML if it could create a claymation video of a black man with large hair asking you to please subscribe to his newsletter, and it did not disappoint.
I grabbed a photo from Equitech Tuesdays at Guilford Hall Brewery by photographer Ian Harpool to check out how well it adds motion to existing images. First, let me show you the original photo:
c/o Ian Harpool This is the video generated from that photo:
Pika
Pika has some extra abilities, including the power to dynamically add sound effects to your generated videos, take an existing image or video, and sync the person’s mouth to an audio clip. Pika also supports the same features as RunwayML, such as video from prompts, video from existing images, and the ability to extend an existing image. Some of these features require a paid account, but you can get a feel for the model’s abilities using the free plans.
I also asked Pika to generate a video of a 3D closeup of a black man with large hair frantically telling people that the M&M vending machines are spying on us (You’ll understand when you get to the p.s.).
I asked Pika to convert that same existing image to video, and it came back with this:
Of course, these are early days, and plenty of video-generating AI models are getting closer to show time. Stability AI, makers of Stable Diffusion, released an early version of Stable Video – an open model you can download and stand up on your own hardware. I’ve personally dabbled with a handful of video models on Huggingface that show tons of possibility. These things are getting better and better. Now, my thoughts on tech & things:
⚡️I believe that the quality of Google Search has been declining for years. However, combining AI and large media organizations employing extensive SEO tactics to sell affiliate products has taken a significant toll, making Google Search quite subpar. I suspect that Google is feeling the pressure from newer AI search upstarts like Perplexity AI and has finally taken steps to weed out the worst offenders.
⚡️Anthropic recently released a new family of AI models and compared them to OpenAI’s ChatGPT 4, but what does that really mean? To date, many AI companies have declared the greatness of their models based on how well they can pass medical exams or the bar. However, that’s not how we use these AI assistants in our daily lives. I want to know if an AI can tell me how much water to use for long-grain rice versus jasmine rice or if it can check my estimates on conversion rates. Techcrunch has a great piece on why AI benchmarks seem to tell us so little when it comes to our everyday use of AI models.
⚡️Apple’s reactions to the EU’s DMA (Digital Markets Act) have felt uncharacteristic for the company, which seems to have done everything it can to meet the letter of the law and nothing more. The most recent blip was Apple’s sudden banning of Epic Sweden from opening its own App Store marketplace in the EU, followed by Apple quickly reinstating it. John Gruber has a good write-up of what happened.
⚡️A company at SXSW used generative AI to bring Marilyn Monroe to life through an interactive bot that mimics her voice, emotions, and physical reactions. The world of digital avatars continues to feel like the uncanny valley but it also opens the door for some truly interesting possibilities.
⚡️After last year’s tumultuous events at OpenAI, which saw Sam Altman fired, two CEOs hired, and Sam Altman rehired, the company finally completed its investigation, returning Sam Altman to OpenAI’s board. The whole saga has been fascinating to watch, and now, Elon Musk – who donated millions to help start OpenAI – is suing the company. This has led to a rather public exchange of words and the public sharing of past emails on OpenAI’s website.
This week, I had a great time delivering an introductory AI talk to the Tristate HR Association at Rowan College in Southern New Jersey. I walked the group through how AI works and its history. I also offered some interactive demos of creating chatbots using OpenAI’s assistants that can answer questions about HR policy from employee handbooks or API calls to HRIS (Human Resources Information Systems).
I have more of these talks lined up and would love to speak at your next event or conference or craft a private talk on how your organization can use AI. I’m also working to launch in-person and online half-day workshops, so keep your eyes open or check out my website for more information and availability.
-jason
p.s. A facial recognition-equipped M&M vending machine on a college campus was discovered thanks to an error message. The company uses it to understand buyer demographics better and determine repeat visitors, but it seems unnecessary.
-
Issue #37: Augment your AI Models with Living Realtime Data
Howdy👋🏾, users of many AI models like ChatGPT reported hallucinations when asking for real-time stats during the Super Bowl. The issue is that AI learns from past data, not present events. At OpenAI DevDay, Sam Altman apologized that the data feeding ChatGPT lagged by years, promising to keep the data cutoff more current going forward.
This lag by design limits the types of queries current AI models can accurately answer. I need real-time info on the weather or live sports scores. Chatbots built on models like ChatGPT are trained on past data so they can’t update you on recent events like a rescheduled volleyball game. As IBM researchers noted, many foundation models essentially take closed-book tests, where that book is slightly out of date.
To address this, models can use Retrieval-Augmented Generation (RAG). RAG realizes when a question requires fresher data and fetches it from APIs, databases, or other real-time sources to augment the model’s existing knowledge. It’s like an open-book test that consults Twitter or Google for a boost. For example, the model could call the weather channel API to answer a question about next week’s weather to provide the most accurate forecast.

Perplexity AI exemplifies this approach. It understands questions via Natural Language Processing (NLP) to extract key points for search. It then scans its own data, APIs, and alternate sources to find insightful, up-to-date information to improve its answers, avoiding hallucination. This combines the power of foundation models with access to living data sources. This approach makes its results very accurate, and it is now one of my favorite places to ask complex questions on the Internet.
I’ve experimented with basic examples of using RAG with OpenAI’s Assistants in my playground test environment. Assistants allow you to define functions – a form of RAG – that get called when the context of a question matches the description you provide.
In the code block above, I define a weather function and provide details to help the AI model know when to utilize it. The code specifies required or optional parameters like “the city” to get the weather. If I ask “Should I wear shorts or a jacket to New Orleans next weekend?” the Assistant can infer I want current weather data. It will invoke my function, passing “New Orleans” as the city parameter and potentially detecting that I need a future weather timeframe.
In my playground, Mavis “Ace” Jarvis, my personal assistant, will take requests for weather or stock prices and call open free APIs to retrieve the latest data. It then uses those real-time responses to augment its knowledge when formulating a final answer.
We could expand this concept across many data sources – like getting the rescheduled volleyball game time or the status of support tickets from systems like Jira and Zendesk. For example, on my playground, Samantha “Smiles” Miles calls a mock API that returns a list of open tickets. It allows you to then ask for updates on any of those tickets. This mock API demonstrates how we could tie into various real-time internal data systems – from prices to employee PTO data – to enable richer responses.
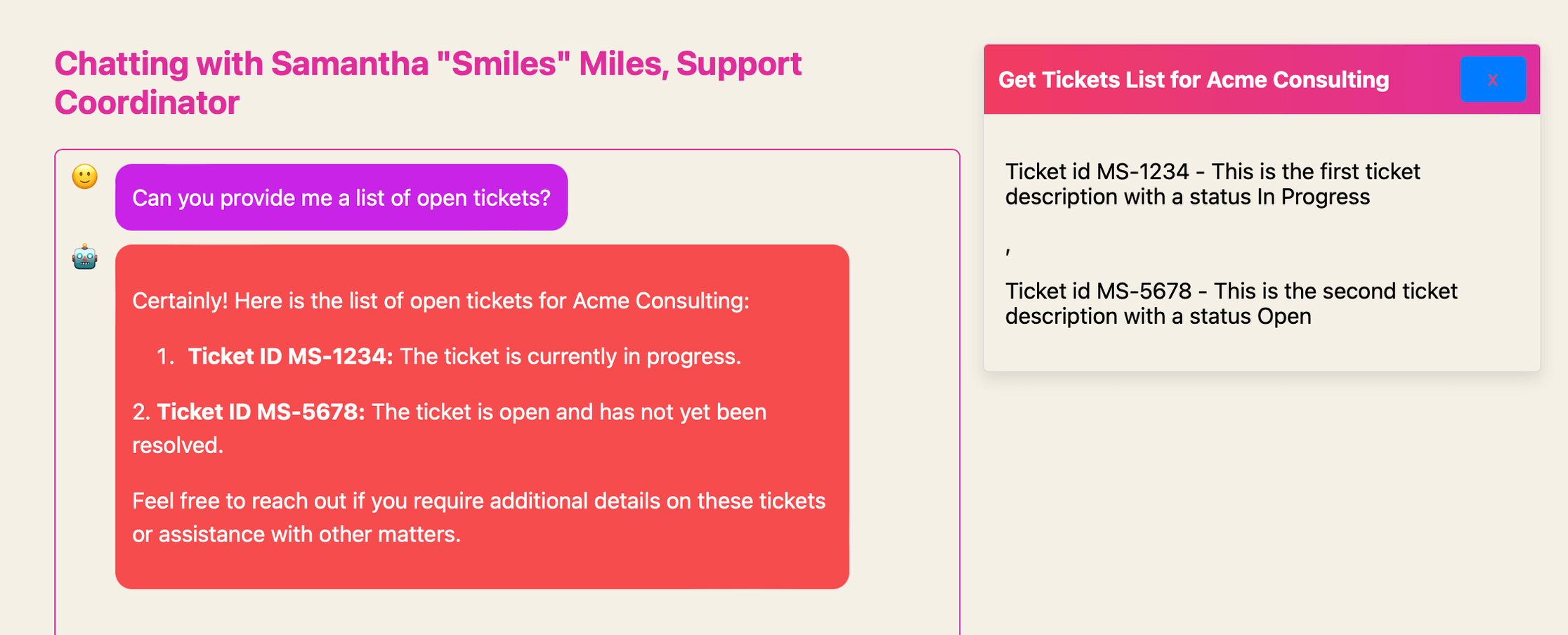
Foundation models are amazing, but the real power of AI comes from a robust multi-model strategy. This approach combines AI models with external data sources like databases, APIs, CRMs, and websites that provide fresh, specialized information. The AI models handle what they have been explicitly trained for, while the living data sources supplement and augment that knowledge. With this combined approach, you can deploy solutions that avoid hallucination and stay current, delivering accurate responses no matter the question. Now, onto my thoughts on tech & things:
⚡️App Clips (instant apps on Android) are drastically underused. This feature allows a QR code or map link to trigger a thin version of an app that does not require a user to download the full app. For example, imagine scanning a QR code on a bill and paying it with an app that’s instantly downloaded. Play has a pretty amazing use case for App Clips that allows anyone to prototype an app and distribute it to investors using this feature. Absolutely a brilliant idea!
⚡️Epic has decided to accept Apple’s offer and release its App Store in the EU, potentially making Fortnite available for installation again for iPhone users in the EU. Apple’s rules charge per install, but Epic’s model is less about installs and app updates and more on SaaS services and virtual currency. More to come, but it is a place to keep an eye on.
⚡️If you missed it, Mark Zuckerberg gave his review of Apple Vision Pro, and surprise he thanks Meta Quest 3 is a better bang for the buck. I shared my thoughts on my blog, and I think Meta needed competition in the mixed-reality space, and this renewed competition will improve the next versions.
OpenAI functions are one way to implement RAG. Cloud platforms like Azure, GCP, and AWS also offer options to connect AI models to live data sources easily. When architecting AI, view it as part of a broader stack, leveraging two tiers of data: relatively static information that trains models and real-time, augmenting data via RAG.
For example, you could train a product support model on a database of specs, descriptions, etc. But data like prices and inventory change frequently, so supplementing with current API data enables accurate responses about new or out-of-stock items. The key is strategically segmenting data as an evergreen foundation vs dynamic augmentation.
An effective strategy for ingesting and partitioning training vs real-time data is just as crucial as data quality. Don’t ask AI models closed-book questions when you can provide open-book advantages with the right architecture. Apply RAG principles to give your models an unfair, data-fueled edge!
-jason
p.s. CaliExpress, a restaurant in Pasadena, CA, has opened a fully autonomous AI – powered restaurant. Yep, you heard that correctly. Fries and burgers are cooked by robots and ordered through an interactive kiosk. I need to schedule a trip out west for some taste testing.
-
Issue #33: Training A Smarter AI with the Tokens of Power
Howdy 👋🏾, earlier this year, I launched a little AI playground for testing various models with the same prompt – an experiment allowing head-to-head comparisons evaluating output differences. My AI playground app is still in beta, so pardon any rough edges, but I did take a little time to drop some new additions this weekend:
- Added Perplexity.ai – the latest trendy AI for developers to tap cutting-edge capabilities
- Integrated the hugely multilingual BLOOM model for broader global applications
- Built text-to-speech using quality OpenAI voices
- A parts of speech tool to test tokenization and how natural language processing works
Keep checking back for more updates! I’m running most models on free tiers and token caps, so I apologize if we hit any caps. If you’re interested in sponsoring to cover compute costs and expand the playground, reach out.
Using any of these models is as simple as typing a prompt, but behind that string lies some interesting complexity. When you submit a text prompt, many AI models first preprocess this with natural language processing or an NLP tool called a tokenizer. A tokenizer splits our phrase into individual words, or “tokens,” allowing isolated examination to discern relationships in the sequence. Take the question – “What color is the sky?”. Tokenizing this yields:{“what”, “color”, “is”, “the”, “sky”}
Creating tokens by word is easy but can require a substantial dictionary in the AI model to understand every possibility. Some tokenizers break up a phrase into subwords or separate modifiers like “eating,” becoming “eat,” and “ing.”
Next, natural language processing identifies part-of-speech and grammatical roles. The NLP tagger labels “sky” as a noun, “color” as a noun, and “the” as a determiner. Understanding role context allows sensible analysis.
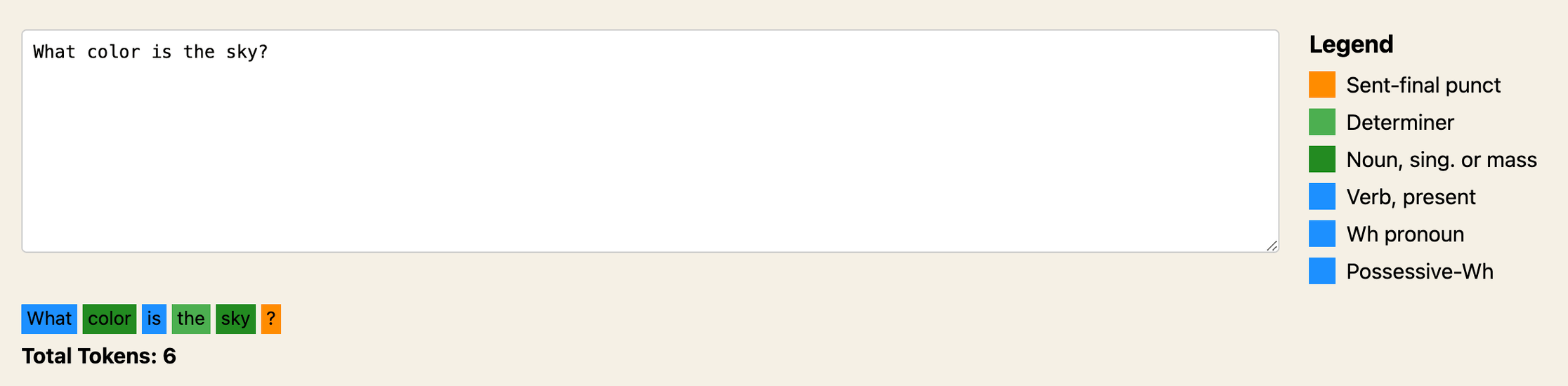
Try it out at https://labs.jasonmperry.com/parts-of-speech These same strings of text we use for our prompts are the same as the structured or unstructured data we use to train AI models. You can imagine developers feeding an AI model content. You might picture a conveyor belt of books, articles, newspapers, and more being dropped into a robot brain a token at a time.
Each of those tokens is used to build a graph that relates words to one another based on how they relate to other words and their usage.
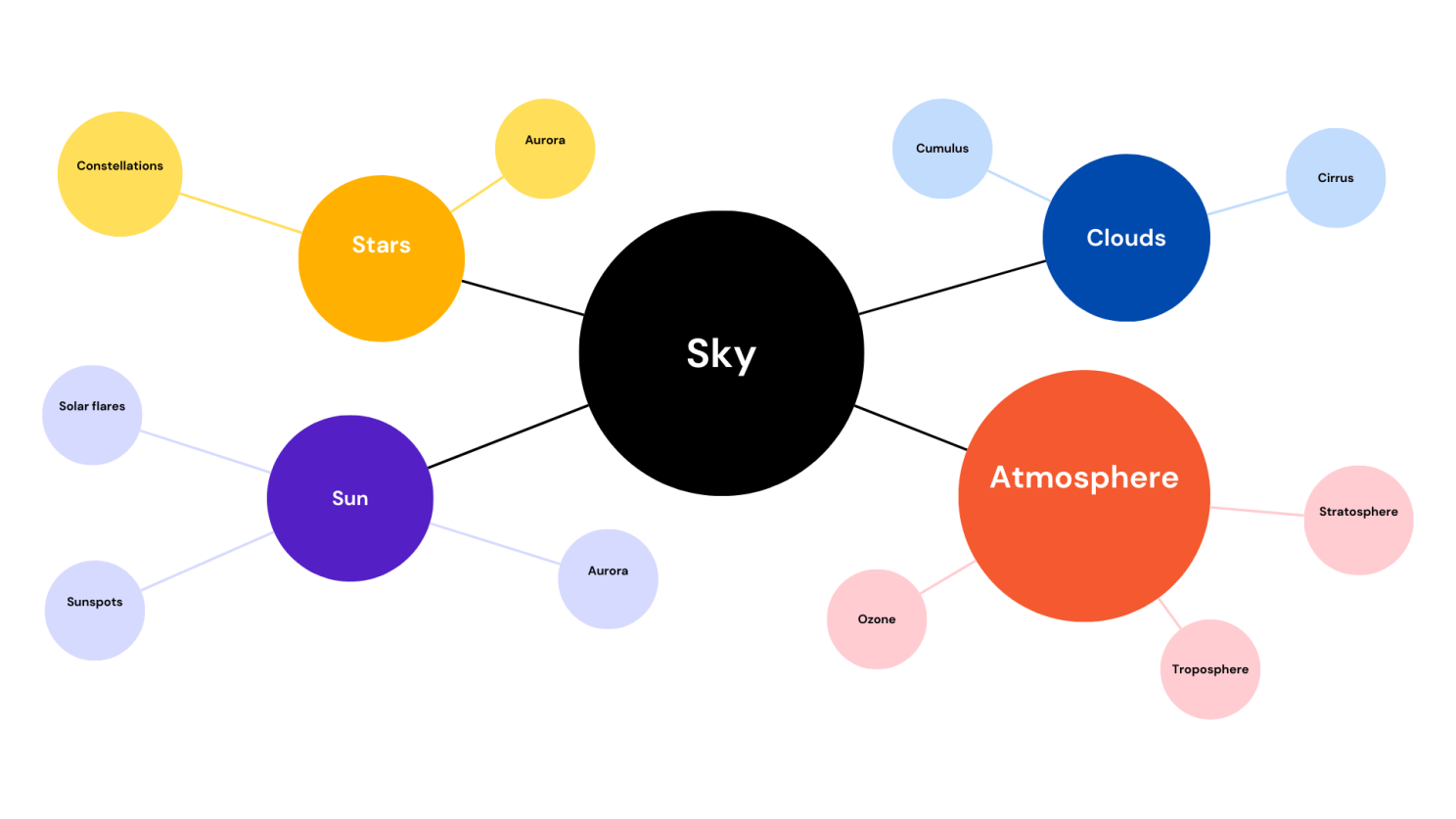
This graph shows words based on the strength of the relationship to a word or the similarity between the words. So for the token “sky,” we might see “atmosphere,” “sun,” “clouds,” and “stars.” This relationship lets us see how a model may infer or understand what something means, and each of these values maintains a weight from +1 to -1 that shows how close a token relates based on the context. Tokens with a negative weight represent opposites like “underground”.
Tokenizers offer valuable insights into an AI model’s text processing. Some may recall the tricky question I posed to various AI models, ‘What might Paris Hilton like about the Paris Hilton?’. The complexity arises as numerous nouns make the part of speech for nouns challenging to decipher, resulting in a complex and confusing graph.
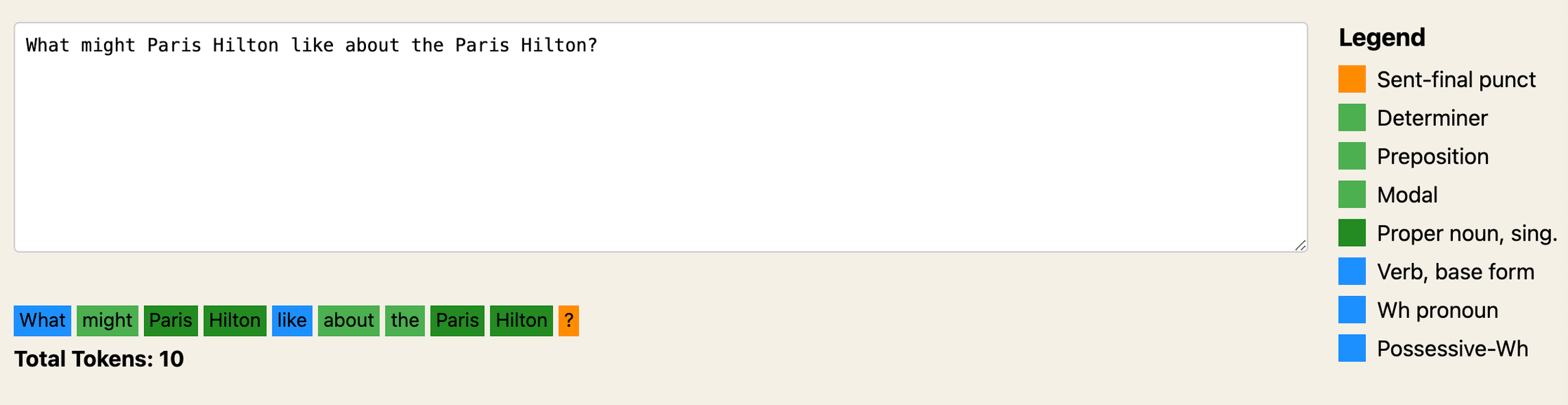
Try it out at https://labs.jasonmperry.com/parts-of-speech Models also give precedence to the order of tokens. While image generation models, especially those accepting shorter prompts, demonstrate this more evidently, the phrase ‘My favorite fruit is mango slice’ emphasizes my favorite fruit as mango over slices. In contrast, ‘Slices of mango are my favorite fruit’ subtly shifts the focus to slices of mango in interpreting the images.

These two images are generated with the prompt “Slices of Mango are my favorite fruit,” with the left from DALL-E and the right from Stable Diffusion 
These two images are generated with the prompt “My favorite fruit is mango slices” with the left DALL-E and the right Stable Diffusion Text completion prompts often prefer right-to-left emphasis, especially with models that offer large context windows like text-to-text or completion generators. Suppose the left represents the history or the past. Text generators have more and more history from previous messages to the left and assume the right represents newer and fresher content. This allows you to better control the response by focusing on the most important tokens to the end or right of a message. You can discern a model’s preference by observing its reaction to the placement of key information, like a 200-character limit.
For instance, let’s experiment with token emphasis from left to right:
“Compose a 200-word article on the impact of artificial intelligence on healthcare, focusing on the advancements in disease diagnosis and treatment.”
If you test this, many popular LLMs may ignore the word count and focus on the article. Now, let’s shift the emphasis from right to left:
“Compose an article on the impact of artificial intelligence on healthcare, focusing on the advancements in disease diagnosis and treatment in 200 words.”
If you run this in your favorite model, notice how the placement of the 200-character limit influences the model’s response, highlighting the nuanced emphasis based on token positioning.
“Tell me about AI in healthcare.”
Remember, if you overlook these nuances and omit key details, forcing the AI to assume the outcome may not meet expectations. You’re welcome. And now, onto thoughts on Tech & Things:
⚡️ With 180,000 Vision Pro pre-orders but just 150 apps, Apple’s mixed reality play faces developer resistance – but is it deliberate protest or practical reluctance?
⚡️ Mia Sato’s recent piece on the quality of search results and SEO, featured on Marketplace and The Verge, sheds light on the declining quality of search results across platforms like Google. Sato highlights the growing concern that SEO practices contribute to homogenizing web design. The pressure to optimize for search engines may lead to many websites looking remarkably similar.
Large language models use a complex graph of tokens and vector databases to craft responses based on the likelihood of the next word in a sequence. If that sounds like gobbly gop, think of completing the sentence ‘Jack and’ as assembling a puzzle. Adding ‘Jill’ is akin to placing a puzzle piece (token) to construct a meaningful picture (output statement). Our advanced language model settings empower us to fine-tune an obvious answer like “Jill” or embrace variety, whether it’s favorable or not. The untold stories of Jack and Ayanna can be shaped with just a tweak of these properties:
- Temperature: Think of temperature like a cooking flame. Higher temperature (hotter flame) gives you more focused tokens, while lower temperature (cooler flame) introduces more random tokens.
- Top-K: Imagine you have 10 flavors of ice cream, and you pick your top 3 favorites (that’s Top-K = 3). Those 3 are what the shop will choose from to serve you a cone. If you increase Top-K to 5, you allow them to pick from more of your favorites, but the flavor they ultimately grab might not be in your top 3.
- Top-P: Now imagine there are 100 flavors to choose from. Top-P is like asking for a scoop with at least 30% of your favorite flavors (that’s Top-P = 0.3). So, at least 30% of the scoop is bound to be flavors in your top favorites. Make Top-P higher, and you get more of a guarantee that the predominant flavors will be your top preferences. But set it too high (like 90%), and you may end up with less variety.
- Frequency Penalty: It’s like adding more unique spices to a recipe. Frequency Penalty lowers the dominance of common tokens or ingredients, making the dish more diverse.
- Presence Penalty: Consider telling a story. Presence Penalty ensures you don’t repeat the same words too often, making the narrative more engaging.
The newly added Perplexity AI model in the playground invites you to explore these settings across various models. Give it a try and see the creative possibilities unfold!
-jason
p.s. I’m thrilled about finally giving Apple’s Vision Pro a try! We’re actively developing new apps for clients and preparing existing ones for this device. However, I haven’t had the opportunity to experience it firsthand; my interaction has been limited to what I can see in the simulator. Watching this video showcasing the making of the Vision Pro triggered my Apple fanboy excitement! I can’t wait to get my hands on it. If you’re curious how it might work, this video walkthrough is excellent.
-
Issue #62: My Tips for ChatGPT and Writing Great Prompts
Howdy👋🏾. I recently delivered an AI talk for the University of Baltimore’s AI in Practice series, and I was asked a question I often get at these events. What are my recommendations for writing better prompts and avoiding hallucinations? So this week, I thought I’d put together my top tips for getting the most out of ChatGPT and other AI models.
When writing a prompt the most important thing is being clear and detailed about what you’re asking. One of the easiest ways to trigger a hallucination is by leaving out crucial details, forcing the model to fill in gaps on its own.
For example, questions like “Should I wear shorts next week?” or “Where should I eat for lunch?” are vague. Where is the person located? What kind of food do they like? What’s the weather like next week? Without this context, the AI model will likely generate a response based on guesses, leading to inaccurate or incomplete information. Giving these details and filling in these gaps can fundamentally change the way a model might respond.
For another example, I might ask “Should I bring shorts when traveling to New Orleans in early October?” Or “Where should I bring a pescatarian friend for lunch in the Hampden area of Baltimore for a quick and low-cost lunch?”
The more detail we can offer the better your response, and the less information we leave the AI model to guess or assume.
Of course, adding all that detail can make prompts long and repetitive—especially if you’re constantly providing the same information, like your location. To help with this, ChatGPT introduced two great features, Customization and Memory, which work in the free and paid versions of ChatGPT.

Customization Options

Customization offers two features:
Your Details: This allows you to provide basic information about yourself so ChatGPT doesn’t require you to repeat it constantly. For instance, letting it know I’m in Baltimore, MD means I can ask, “Where should I go for lunch?” without re-entering my location every time.
Response Preferences: You can set how you want ChatGPT to respond—whether you prefer a formal or casual tone, more concise replies, or even responses that include jokes. This feature saves time by applying these settings to every chat.
This information is automatically added to new chat conversations by default by setting these customization options.
Memory Feature

Another useful feature is Memory. While custom instructions set general guidelines for how ChatGPT responds, the memory feature learns from your ongoing conversations, storing information to provide better answers in the future. You can review or delete memories whenever you like, ensuring ChatGPT evolves to suit your needs while respecting your privacy.
If you mention something ChatGPT sees as potentially relevant for future conversations, like your favorite color, or type of food, or you ask it to remember something for future chats it will add it to the memory and store it.
Making an Agent
Once you’re ready to write a prompt, remember that prompts do more than ask questions. They can set ground rules, provide a personality, or specify how ChatGPT should handle the interaction.
For example: “Your name is Zara, and you are a business advisor and marketing expert. You help large entrepreneurs and business owners nail down their start-up ideas, understand finances, create pitch decks, create elevator pitches, and focus on the go-to-market strategy. You’re concise and friendly but not afraid to deliver bad news.”Starting with a prompt like this, helps the context of a chat understand the role it should look at and understand information. Of course, don’t stop here, you want to add details about the business and any issues you need help with.
Keep in mind that ChatGPT can easily read through files – so upload a copy of your business plan, pitch decks, or other documents and it will absorb that information and use it in its analysis.

If you’re worried that ChatGPT might take this proprietary data and use it to train, always remember that in settings, under Data controls, you can deselect the default option to use your chats to improve the model.
Know the Limits
Finally, understand the limitations of AI. “LLMs are software systems, and by nature, they struggle with understanding the concept of time. These models are trained on vast amounts of data, but their intelligence and knowledge are limited to the age of that data, which is usually months old if not years old. This is crucial to remember because AI won’t know today’s date, the current weather, breaking news, details on the recent presidential debates, or the score of the latest Saints game.
Some AI models use Retrieval-Augmented Generation (RAG), which integrates real-time information from sources like web searches. This helps fill in the gaps where the model’s knowledge might be outdated or incomplete. Systems like Perplexity AI mix in the results of web search with the data of the model to provide more real-time answers – but again the underlying AI model’s normal response is being augmented with the additional information from the search results giving in newfound knowledge it might not otherwise have.
To learn about the limitations of the system you are using occasionally ask simple questions – like inquiring about the current year, the weather, or specific topics you need assistance with. This helps supplement those gaps by giving information through a more detailed prompt or by providing files that include this information.
So, those are some of my OpenAI tips! These tips work for any AI model out there. Now, here are my thoughts on tech & things:
🛡️ Cloudflare Gives Creators Control Over AI Crawlers
Let’s face it—robots.txt wasn’t built for the AI age. Cloudflare now offers website owners a simple way to block AI models from scraping their content, but will this limit your visibility in AI-powered tools?
Read more🕶️ Meta Connect 2024 Kicks Off
Meta Connect kicks off on Sept 25th, and we’re expecting big announcements around new AR, VR, and AI products. Will we also see new Ray-Ban smart glasses and updates to Meta’s Llama AI models?
Read more⚡️The Environmental Impact of AI
Training advanced AI models takes immense power—ChatGPT-3 used as much energy as 120 average households. Microsoft is reopening the Three Mile Island nuclear plant to power its Azure data centers and OpenAI’s future AI models.
Read more
One last tip, there is nothing wrong with starting a prompt again or asking for details to help you move key points from a conversation to a new thread or another AI model. When I’m working with a model on a programming issue, and I’m unhappy with what it has delivered to me so far – ask it to summarize the key points for me to use as a prompt in another AI model.
Quick update:
📕 In case you missed it, AI Evolution is available for preorder! Grab it early to lock in a discount and score exclusive beta reader access.
📺 I posted the full video of my chat with Mindgrub Director of Mobile and Research and Development, Rob Koch on Apple’s big September iPhone event. Check it out.🗣️Exciting events are on the horizon—I’ll be speaking, joining panels, and even moderating. I would love to see you there!
Oct. 5 BarCamp Philly Oct. 21 DC Startup & Tech Week Nov. 7 World Trade Center Institute AGILE Global Innovation Series Dec.12 AI Summit NYC Jan. 7 CES Good luck and happy prompting!
-jasonp.s. 5 years ago, a Redditor posed a simple question—who are the 6 celebrities on a curtain pattern? After years of speculation, Internet sleuths finally identified the mysterious ‘Celebrity Number 6.’ Check out the solved mystery here.

-
Yelp Seizes the Moment After Google’s Antitrust Defeat
In the wake of Google’s recent antitrust loss, it’s clear that Yelp smells blood in the water. Jeremy Stoppelman, Yelp’s CEO, recently penned a blog post announcing that Yelp is suing Google, accusing it of being a monopoly that unfairly suppresses local search results.
Stoppelman makes a compelling case, arguing that Google has been propping up what Yelp calls an inferior local search product to capture more search traffic within its own ecosystem—something widely known as “zero-click search.”
As I’ve pointed out in my newsletter, this couldn’t come at a worse time for Google. For the first time, competitors like OpenAI and Perplexity AI see a path to challenge Google’s dominance in search. But AI-driven search is a different beast, something I’ve referred to as “answer engines.” Unlike traditional search, these tools don’t provide a list of links or drive traffic to the sources they pull from; instead, they deliver direct answers, posing a new kind of threat to Google’s search empire.
-
Issue #53: Apple and Meta’s Latest Mixed Reality Moves
Howdy 👋🏾. Apple surprised everyone by prominently featuring the Apple Vision Pro at its Worldwide Developers Conference several weeks ago. If you follow Apple, there is plenty of reason for concern. Early rumors indicated Apple was cutting its delivery predictions, initial buyers reported high return rates, and several reviewers, including myself, found the app lacking killer features.
However, there was one huge positive: the importance of competition. Meta responded by releasing numerous updates to its Meta Quest devices, reviving forgotten or abandoned features to close the feature gap. Meta also announced a significant reshuffling of its Reality Labs division into two sub-units: one focused on wearables and the other on the metaverse. The metaverse division aims to build out its VR platforms, like Horizon’s social platform and VR headsets. At the same time, the wearables team is set to capitalize on the unexpected early success of the company’s Ray-Ban glasses.

I love the Ray-Bans and have been quite happy with the constant release of features, including adding AI tools to detect objects. Unfortunately, they do not accommodate my prescription for the frames, but I’m hopeful the next set, rumored to include a Google Glass screen, might.

With this new view of the evolving mixed reality market, I downloaded VisionOS 2 beta 2 onto Apple Vision Pro before a quick work trip to New York to see how the system-level changes to the device stand up. Special thanks to Mindgrub for letting me hold on to this headset for a little longer.
But before we dive in, a word from my sponsors and my thoughts on tech & things:
🤝 This week’s newsletter issue is proudly sponsored by:

If you are looking to find amazing people, contact Baird Consulting.
⚡️Anthropic continues to update its AI models with a new release they say matches ChatGPT 4o. What I’m most excited about is a very cool concept called Artifacts. Artifacts allow you to create a shared document space that you and Claude can both share and work on together, and this sounds like a killer feature!
⚡️Apple is buckling down for a huge lawsuit and fight with the EU over the DMA and has now stated that certain features, including Apple Intelligence, will not launch this year, and they don’t know when. Folks have varying views on whether this is a threat from Apple or an issue with a rule that requires interpretation.
Beta means beta, and it’s not uncommon for Apple’s early beta releases to have significant bugs. You never know when a release might cause major issues. Of course, as soon as I got back from camping and had a stable internet connection, I installed all the betas on my TV, watch, phone, laptop, and Apple Vision Pro. Aside from some issues with macOS, I’ve been pleasantly surprised with how complete the betas have felt.
At WWDC, Apple listed an exhaustive array of new Apple Vision Pro features. Some of these are immediately available in the betas, while others, like multi-view, which allows users to watch up to 5 soccer or baseball games simultaneously, are still in development. As I use and test these features, I’ve kept my eyes on how well they address some of my biggest complaints. Here’s what I think so far:
Eye Tracking
Most of Apple Vision Pro’s interface works by tracking what you’re looking at, allowing you to interact with an object by looking at it and pinching your fingers together. I found this frustrating because your eyes drift, or your focus sometimes jumps to your next target without you realizing it. While Apple hasn’t announced changes here, I’ve noticed fewer issues selecting dialogs or smaller elements since installing the beta. This is one of those weird things where you do something that once felt frustrating, and then you realize it wasn’t, but you can’t quite figure out why. I am glad to see this getting improved, and I’m curious to hear if others have felt similarly.
Mouse Support
Apple Vision Pro, at launch, supported Bluetooth keyboards and trackpads but did not provide support for a mouse. I found this odd, but I didn’t expect it to be much of an issue. The problem is that many third-party trackpads present themselves as a mouse, so my portable keyboard and trackpad combo didn’t work. I’m happy to say that these devices now pair and work without issues.
Hand Gestures and Notification Center

Some of the early ideas for how you launch the home screen with apps, access the notification center, or dismiss notifications felt a bit unpolished. The introduction of new hand gestures is a very cool way to fix that. Instead of tapping the digital crown to bring up the home screen with apps, you can now hold your hand out palm up, causing a floating icon to appear. If you complete an “O” with your fingers, Apple Vision Pro will launch or close the home screen without requiring you to touch the device. Turning your hand so the back faces up while holding your fingers together transforms the floating “O” into a display that shows the time and volume, which can easily expand to become the notification center.
It took some trial and error to get used to this action, but once it became comfortable, it felt natural. It also kept me from constantly touching the device, which sometimes required me to readjust from the downward pressure of tapping it.
Screen Sizes
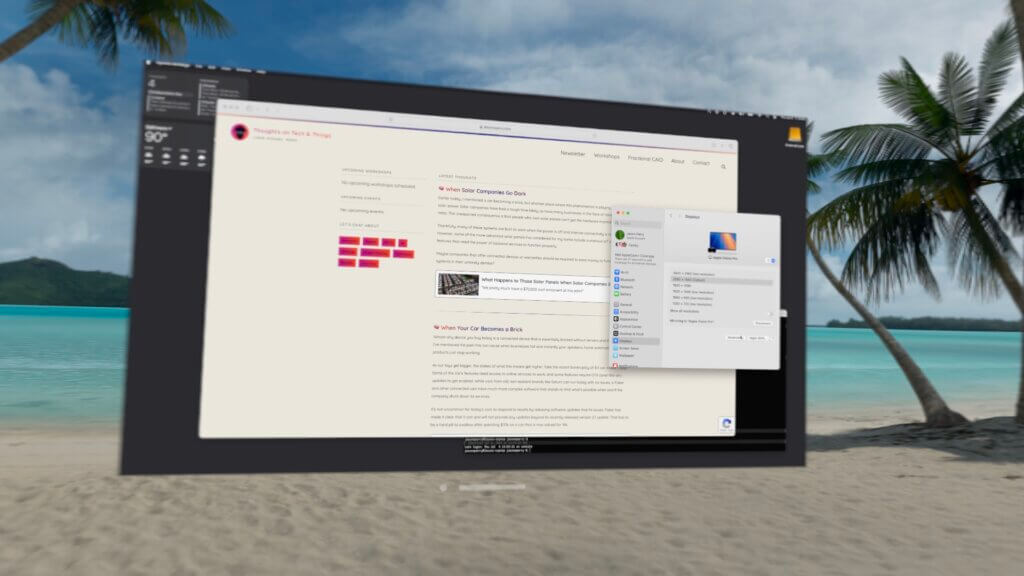
When sharing my laptop’s screen, new settings appear that allow you to adjust the resolution to many additional choices. I love having a large rectangular display that gives me more space to play, and it still connects and works with ease. One promised but still missing feature is the environmental passthrough of an external keyboard, which makes your keyboard invisible when moving into an environment.
Additional Environments
Apple introduced additional immersive environments, including Bora Bora, and I’m already in love with working from the beach. It’s perfect for evenings when I can recline back on my patio, sit on the beach, and listen to the waves as they hit the shore. It is so relaxing and feels like I’m in a Corona beer commercial.
Handling Darkness
Darkness remains an issue, but tracking is better, and in my testing, Apple Vision Pro does a better job of maintaining its position at night. On my patio, as the evening became darker, I received warnings that tracking would become difficult, but it managed to pick up my hands until things got closer to pitch black.
Overall, the updates, while minor, really go a long way to making the device feel complete. This beta reminds me of my experience using the very first Apple Watch, now known as the Series 0. It was an okay device, but over time, operating system updates fixed issues, and the iteration turned an okay device into a good or great device. Apple Vision Pro feels set on that same journey, and I can already tell you that visionOS 2 beta moves it a few notches above ok.
If you like this content, please share it with your coworkers and friends. Also, this a reminder that I’m looking for newsletter sponsors and that I’m available as a fractional Chief AI Officer or a technical consultant.
-jason
p.s. I really love Perplexity AI. I use DuckDuckGo as my default search engine, but that’s due to the muscle memory of searching by typing in the browser’s URL bar. For anything that feels remotely complicated, I hit up Perplexity AI. Wired has a great article on not only Perplexity creating BS but also indexing content when it says it explicitly won’t.
If that wasn’t enough, Perplexity indexed Wired’s article (which blocks AI bots) and created an article about itself using the content of the article! You can’t make this stuff up.
-
Issue #52: Embracing Web 4.0: The Intelligent Web
Howdy 👋🏾. No matter how often I make rice, I need a reminder of the different water-to-rice ratios for different types of rice grains. A Basmati is just a bit different than a Jasmine rice, and as a New Orleanian, serving bad rice is a sin. For years and years, I would do a quick search on Google to confirm. That gradually shifted to me asking Alexa and now Siri, who does a so-so job with responses. If this sounds somewhat normal to you, you already understand why Google Zero and Zero click search results are not only here but inevitable in a world of AI-powered assistants.
This transition is a shift in how we interface with the web, and this evolution has been happening for some time. The primary competitor to the web browser and the open web is the ever-expanding app ecosystem. Several years ago, The Oatmeal posted a comic that still perfectly describes this change, one that is now accelerated by AI.

In a recent newsletter, I covered the death of SEO and how AI is accelerating the death of the open web because it can answer a question using the web as its source but without the attribution or click you might depend on. My question about rice is a prime example. Many articles and recipes exist on the web that explain how to make perfect rice, but my question can be answered without needing me to click in and view ads or note the website the content came from.
In many ways, I see Web 4.0, known as the semantic web or the intelligent web, as a distillation of these ideas. Web 4.0 understands the Internet’s evolution into ecosystems and uses that understanding to reimagine a web where the web browser is not king. I like to think of Web 4.0 as the API-fication of the Internet, where APIs or Application Programming Interfaces speak to the ways we allow computers or ecosystems to communicate with each other. Some of the core tenants include:
Decentralization
Decentralization, which I think is best reflected in the push by the social media platforms Threads and Blusky to accept the Fediverse and open their doors to other ecosystems that manage and maintain their own rules. In a world of AI bots, this becomes incredibly important. For the next generation of personal AI bots to really help us, they need ways that they can interact with other bots or computers to help get the information we need. For example, if you want a plane ticket from Southwest Airlines, it would be great to write a message or ask a virtual assistant something like, “What are the 3 cheapest nonstop flights this Thursday from Baltimore to New Orleans?”. To make this possible, AI will need the ability to bypass a website and ask questions to a company’s APIs, creating a lesser need to flock to a browser.
Artificial Intelligence and User-Centric Design
Artificial Intelligence and User Centric Design speak to increasing depth of customization and personalization. Platforms know a lot about us, and they can use this information to better personalize experiences to match our needs or target content based on our likes. On the web, DXP or Digital Experience Platforms are allowing web and mobile applications to integrate information from CRMs or other data sources to dynamically change the flow of content to cater to a user. TikTok and Instagram have had highly targeted ads for years, but TikTok’s shopping marketplaces are becoming highly personalized shopping malls that cater products to you based on your needs. To date, while possible, true customization has been hard, and the results have been so-so. What is changing is the power of AI tools combined with rich customer information and the ability of these bots to customize messaging that feels truly targeted and human.
Advanced Interactivity
The world of mixed reality has stumbled quite a bit. The AI Pin was a flop, and Apple Vision Pro, while amazing, proved how far these devices might be from the norm. They also reflect our growing need for Advanced Interactivity that moves beyond the keyboard. Voice assistants are an amazing step, but the voice is not always the right tool, especially in busy and noisy environments like offices, buses, or trains. Web 4.0 will help to meld mixed reality experiences and non-keyboard experiences to make the ways we interact with the web different and unique.
IoT or the Internet of Things
Finally, IoT or the Internet of Things is becoming easier with better support for standards like Thread. To date, IoT has been clunky, and interoperability between ecosystems is limited, but this is changing as more devices can easily communicate with one another without needing a developer to configure things. IoT is also evolving in other ways like Amazon’s Sidewalk Network, NFC devices that can share data like business cards and menus, the ability to tap and pay, or features like AirPlay that let you stream music to a device you’re in proximity of.
It’s early in this new wave of an AI-powered, decentralized API-first web that allows for intense personalization, new ways of interacting, and easier connectivity between devices, but the seeds are sprouting. Now my sponsors and thoughts on tech & things:
🤝 This week’s newsletter issue is proudly sponsored by:
⚡️Forbes is taking legal action after Perplexity AI released a beta product that summarizes or answers questions from sourced content. As Forbes put it, the content is directly based on their own but does not properly credit or attribute it while beating them as the original source of the content in search results.
⚡️Tim O’Reilly, creator of O’Reilly Media, has an interesting write-up on AI copyright infringement and some thoughts on how rights holders should get paid. The system is similar to that of streaming music on online training libraries, where a revenue pool is created and paid out based on your percentage of streams. In his model, AI knows the sources of the data it uses to create a response and pays out for the use of that data. It’s interesting and worth a read.
⚡️From the day Zara and I met, I knew it was only a matter of time before an AI-focused social network emerged, and it’s here. I haven’t had a chance to download the app yet, but this is only the beginning of more and more AI-generated content targeted to your personal interest. Crazy time to be alive!
APIs and stronger standards for open communication are going to become extremely important as we embrace Web 4.0 and AI. Many of my enterprise clients are flocking to build large data lakes that pull systems together to create powerful RAG (Retreival-Augmented Generation) data sources that can feed their AI systems. If you want a powerful healthcare AI tool, it must talk with your EHR (Electric Healthcare Record) system. If you want an HR bot, it needs to talk with your HRIS (Human Resource Information System). If you are looking to do something for customers or sales, it probably needs insights into a CRM (Customer Relationship Management) or support and ticketing system.
Those enterprises facing the most difficulty are companies locked into agreements with legacy systems that purposely make it hard to get access to this data or those who build protective walls around their systems to make migration harder or force you to use their own brand of products. This is not just a pain; it’s a setback that will make businesses that can openly access their data unable to compete with those that can.
Thank you to the Baird Consulting Group for being the first sponsor of Thoughts on Tech & Things. If you need help filling a position or find yourself in the market, please reach out to them here or upload your resume to their website.

I am actively seeking additional sponsors for a variety of exciting initiatives. If you or your organization are interested in exploring opportunities, need a fractional Chief AI Officer or AI consultancy, or are interested in participating in one of my workshops, please don’t hesitate to contact me via my website or at jason@jasonmperry.com.
I hope you had time to reflect over the Juneteenth break, and I’ll see you all next week.
-jason
p.s. I guess AI more than mimics reality. A competition for the best AI-generated photo disqualified one of its winners after the photographer admitted that it was a real photo and not actually AI-generated.

-
Issue #50: SEO is Dead
Howdy 👋🏾, when Google released its new AI Search Overviews at Google I/O, I felt a great disturbance in the Force, as if millions of SEO specialists and content creators suddenly cried out in terror and were suddenly silenced. I fear something terrible has happened.
AI Search Overviews provide summaries or direct answers to users’ search queries generated from Google’s Gemini AI model. The idea is to help users get answers quickly without searching through search results. Have a question about Frederick Douglass? Google can now answer that directly with an AI-generated overview.

The obvious fear is that features like this create what The Verge’s Nilay Patel calls Google Zero, or what is known in the industry as zero-click search. Users search Google and get an answer sourced from content written by you, but all the interaction happens on Google without traffic sent to your website.

For years, many have felt Google has focused on building a moat around its search services, pushing users to interact with Google’s ecosystem rather than search results. If you search for a product, you’re met with Google marketplace links. Look for a restaurant, and Google’s business profiles and map results dominate the page, followed by sponsored ads. These changes push valuable page 1 links lower, generating less traffic.

It’s easy to blame Google, but our search habits have evolved. AI overviews are just the latest reminder. Take voice-powered gadgets like Alexa, Siri, Google Assistant, or Cortana. If you ask about Frederick Douglass, the distance to Trader Joe’s, or the ratio of jasmine rice to water, the last thing you want is a page of search results. You want a direct answer, something AI-powered systems can provide by consuming content from other sources.
Voice assistants are not the only competitors to search. Increasingly, AI tools like ChatGPT and Claude are taking what may have once started as a search query and giving back answers. Do you need help with your resume? Are you struggling to write a job description? ChatGPT is often a much better starting place than search, and while the data for these answers may have come from your content, you’re not getting attribution or traffic.

Perplexity AI, a search engine I love and often mention, exemplifies what search might evolve into. You ask a question, and using AI and RAG (Retrieval Augmented Generation), it searches through curated responses and returns an AI-summarized answer. It’s the best of both worlds, coupling the abilities of AI assistants with the power of curated search results. The web pages that generate these answers are linked as sources, but how many of us will click to read those links?
Media outlets, blogs, and product companies are already noticing these trends. Search traffic has been declining for years. Gartner believes search traffic will drop by as much as 25% by 2026, and I think those numbers are extremely conservative. For evidence, read HouseFresh’s managing editor blog post on the site’s battle with Google search and her excellent follow-up; that begs the question, what do you do when all of that search traffic disappears?
Google Zero is here for some; AI-powered search and assistants will hasten it. It’s not crazy to imagine that jockeying for page 1 of search results in a few short years might be just as important as showing up first in the Yellow Pages. So, SEO may not be dead yet, but now may be a good day to start imagining where it is tomorrow. Now, my thoughts on tech & things:
⚡️ ️Rumor has it that Apple and OpenAI just inked a deal for the company to power AI in the Apple ecosystem. I’m still betting that most of the AI happens locally on the device, but it reaches out for more extensive calls. That said, this deal seems to have required Altman to calm fears with Microsoft. Apple’s WWDC is June 10th, so we might know what we’re getting soon.
⚡️Google has confirmed a huge leak of internal documentation on search, which has some wondering how truthful the company has been on how search actually works. Search Engine Land has the SEO breakdown on what it means.
⚡️Snowflake security breach – stay tuned…
Discovery on the Internet feels harder than ever, as does the value of a website in a world of increasingly closed systems and communities. I’m amazed by the number of influencers on platforms like YouTube, Instagram, and TikTok who don’t have websites. Can you imagine a large brand like Ford, Apple, or GM existing without a website? Yet folks like Mr Beast don’t live on the open web; they live in ecosystems like YouTube and Instagram.
Trends have been shifting from the open web and search for some time, and chances are you spend more time today in a closed ecosystem than you do jumping from web page to web page. Your product purchases and news habits are now governed more by social media communities or content aggregators like Google News or Apple News.
When I talk with clients, I find that many have replaced search traffic for discovery with one of these ecosystems that they increasingly feel beholden to. For influencers, it’s YouTube, Instagram, and TikTok. Businesses and job seekers live on LinkedIn. Restaurants depend on Yelp and Google Maps; for delivery, they depend on DoorDash and Uber Eats. Retailers live on Amazon, Etsy, and Shopify. Writers and bloggers have flocked to Substack and Medium. Software developers depend on the Apple App Store and Google Play Store. Game developers live on Steam. Movie and TV producers live on YouTube and Netflix.
The open web, which is the heart of search, is dying. It’s harder now to simply put a web page or blog on the web and survive without finding an ecosystem, and those who try to survive without them are finding Google Zero is forcing their hand.
As SEO becomes less relevant, the future of digital marketing and discovery is shifting towards ecosystem marketing. This involves understanding and leveraging which ecosystems drive AI tools and user interactions. Curated and trusted sources like Wikipedia, Yelp, and Reddit are becoming powerful aggregators for AI-powered assistants. It makes groups like OpenAI keen to negotiate deals with these ecosystems to get that valuable data.

Perplexity AI allows focuses that can limit the systems it sources to particular data ecosystems. Apple Maps sources much of its data from Yelp, though it has begun collecting its own data. One can imagine that this will factor even more significantly when AI assistants like Siri suggest dining options nearby. Owning your presence in these ecosystems will be crucial to becoming the new #1.

I have two milestones to celebrate. This Friday marks my last day at Mindgrub, and this newsletter you’re reading is issue #50! It’s strange looking at the first issues and watching as some of my early ideas began to take shape. As always, I really hope you all enjoy the read, and if you do, please forward, share, or comment.
Also, don’t forget that if you or someone you know needs AI consulting, support from a fractional CTO or CAIO, or to check out one of my workshops, don’t be a stranger and reach out.
-jason
p.s. Every ecosystem comes with rules, and those rules can drive you crazy. If you own an LG or Samsung washer machine, you may have noticed it plays a little Diddy after a cycle is complete. One YouTuber lost untold amounts of cash after copyright claims were made on the public domain Samsung chime in his video streams. ArsTechnica takes a deep dive into content creators’ continued struggles with YouTube content ID. Enjoy the many sounds of washers and dryers.
I think I like LG’s the best.
-
Is Apple About to Buy an Answer Engine?
What do you do when $20 billion in revenue might vanish thanks to Google’s looming antitrust fallout?
You buy the best damn answer engine on the block.
Perplexity is already my favorite AI search tool—fast, smart, and actually useful. Imagine it embedded deep into Apple’s many operating systems. A real-time answer engine that could make Siri useful and launch a day-one Google Search competitor. If this happens, it might be Apple’s smartest acquisition in years.
-
Bye SEO, and Hello AEO
If you caught my recent LinkedIn post, I’ve been sounding the alarm on SEO and search’s fading dominance. Not because it’s irrelevant, but because the game is changing fast.
For years, SEO (Search Engine Optimization) has been the foundation of digital discovery. But we’re entering the age of Google Zero—a world where fewer clicks make it past the search results page. Google’s tools (Maps, embedded widgets, AI Overviews) are now hogging the spotlight. And here’s the latest signal: In April, Apple’s Eddy Cue said that Safari saw its first-ever drop in search queries via the URL bar. That’s huge. Safari is the default browser for iPhones and commands over half of U.S. mobile browser traffic. A dip here means a real shift in how people are asking questions.
I’ve felt it in my habits. I still use Google, but I’ve started using Perplexity, ChatGPT, or Claude to ask my questions. It’s not about keywords anymore, it’s about answers. That brings us to a rising idea: AEO — Answer Engine Optimization.
Just like SEO helped businesses get found by Google, AEO is about getting found by AI. Tools like Perplexity and ChatGPT now crawl the open web to synthesize responses. If your content isn’t surfacing in that layer, you’re invisible to the next generation of search.
It’s not perfect—yet. For something like a recipe, the AI might not cite you at all. But for anything involving a recommendation or purchase decision, it matters a lot.
Take this example: I was recently looking for alternatives to QuickBooks. In the past, I’d Google it and skim through some SEO-packed roundup articles. Now? I start with Perplexity or ChatGPT. Both gave me actual product suggestions, citing sources from review sites, Reddit threads, and open web content. The experience felt more tailored. More direct.

If you sell anything—whether it’s a SaaS product, a service, or a physical item this is the new front door. It’s not just about ranking on Google anymore. It’s about being visible to the large language models that shape what users see when they ask.
So, you’re probably asking. How do you optimize for an answer engine? The truth is, the rules are still emerging. But here’s what we know so far:
• Perplexity leans on Bing. It uses Microsoft’s search infrastructure in the background. So your Bing SEO might matter more than you think.
• Sources are visible. Perplexity shows where it pulled info from—Reddit, Clutch, Bench, review sites, etc. If your product is listed or mentioned there, you’ve got a shot.
• Wikipedia still rules. Most AI models treat it as a trusted source. If your business isn’t listed—or your page is thin—you’re missing an easy credibility signal.But the biggest move you can make?
Start asking AI tools what they know about you.Try it. Ask ChatGPT or Perplexity: “What are the top alternatives to [your product]?” or “What is [your business] known for?” See what surfaces. That answer tells you what the AI thinks is true. And just like with Google, you can shape that reality by shaping the sources it learns from.
This shift won’t happen overnight. But it’s already happening.
Don’t just optimize for search. Optimize for answers.






