
Latest Thoughts
-
🧠 AI is sprinting, and this week’s pace was dizzying!
At Microsoft Build and Google I/O, we saw a flood of dev-focused announcements, new models, better tooling, and smarter assistants. OpenAI shook things up with its surprise acquisition of IO, the design-forward startup from Jony Ive that had already picked up Wind Surf and its “vibe coding” platform.
But Anthropic quietly dropped what might be the most impressive update of the week: Claude 4. Analysts are calling it one of the best coding models released to date. And here’s where things get really interesting: rumor has it Apple is prepping a Claude 4 integration directly into Xcode. WWDC is around the corner, and if true, that could mark a major shift in how Apple plans to close the AI gap.
Every player is pushing forward. The race isn’t just about general intelligence anymore – it’s about who can make AI feel seamless, useful, and built-in for developers. -
The AI Evolution: Approaching Data and Integration
“I’ve seen things you people wouldn’t believe.”
– Roy Batty, Blade RunnerWorking in consulting gives you a kind of X-ray vision. You walk into a room with a new client and they start listing all the reasons they’re unique—how no one understands their business, how their systems are one-of-a-kind, how the complexity of what they do defies replication. And sure, some of that is true. Every organization has things that make it unique and its oddities. But once you get past the surface, you usually find something that feels familiar: a recognizable business structure layered with years of adaptations, workarounds, and mismatched systems that were never quite built to talk to each other.
When it comes to AI, this same story plays out over and over again. We start talking about the opportunities—where it could go, what it might unlock—and then we hit the same wall: the data. Or more accurately, the data they think they have.
Here are some common refrains I’ve heard across industries:
• “Those two systems don’t talk to each other.”
• “That data is stored in PDFs we print and file away.”
• “We purge that information every few months because of compliance.”
• “It’s in SharePoint. Somewhere. Maybe.”
• “Our marketing and sales platforms use different ID systems, so we can’t link anything.”
None of these answers are surprising. What’s surprising is how often people are still shocked when their AI project struggles to get off the ground.
In our survey, 44% of business leaders said that their companies are planning to implement data modernization efforts in 2024 to take better advantage of Gen AI.
PWC 2024 AI Business Predictions
This chapter is about getting real about your data. Before you can build intelligent systems, you have to integrate them. And before you can integrate them, you have to understand what data you have, where it lives, what shape it’s in, and whether it’s even useful in the first place.
Most companies assume their data is more usable than it actually is, which creates the Illusion of Readiness.
They picture their systems like neat rows of filing cabinets, all labeled and accessible. The reality is more like a junk drawer: some useful stuff, some random receipts, and a bunch of keys no one remembers the purpose of.
And here’s the kicker: AI doesn’t just use data. It relies on it. Feeds off it. Becomes it. If you give it bad data, it doesn’t know any better. It won’t tell you it’s confused. It will confidently give you the wrong answer—and that can have consequences.
Before we get into the mechanics of how AI consumes data, we need to talk about what kind of AI we’re actually working with.
The term you’ll hear a lot is foundation model.
These are large, general-purpose AI models trained on vast swaths of data—think billions upon billions of pieces of information. They’ve read the internet. Absorbed the classics. Ingested code repositories, encyclopedias, manuals, blogs, customer reviews, Reddit threads, medical journals, and everything in between. Foundation models like ChatGPT, Claude, Gemini, and Llama are built by major AI labs with enormous compute budgets and access to vast training sets. The result? Models with broad, flexible knowledge and the ability to respond to all sorts of queries, even ones they’ve never explicitly seen before.
To understand how these models work—and how you’ll be charged for them—you need to know about tokens.
A token is a unit of language. It’s not quite a word, and not quite a character. Most AI models split up text into these tokens to process input and generate output. For example, the phrase “foundation models are smart” becomes something like: “foundation,” “models,” “are,” “smart.” Each token costs money to process, both in and out. That means longer prompts, longer documents, and longer replies increase your cost.
But it’s not just about billing. Tokens define the model’s short-term memory, called the context window. Each model has a limited number of tokens it can “see” at any given time. Once you exceed that limit, earlier parts of the conversation start to fall out of memory. This is why long chats start to lose focus—and why prompts or instruction sets, RAG results, and injected context have to be compact and relevant. The more efficient your language, the smarter your AI becomes.
But not every task needs a giant model.
If you’re running a chatbot that answers routine FAQs, sorting support tickets, or parsing form submissions, a smaller and faster model will likely serve you better—and at a much lower cost. Foundation models are impressive, but they’re not always the most efficient tool in the toolbox. The art of modern AI isn’t about grabbing the biggest brain in the room. It’s about choosing the right model for the right job—and knowing when to escalate to something more powerful only when the problem truly demands it.
They’re called “foundation” models for a reason: they serve as the base layer on which other, more specialized AI systems are built.
But here’s the catch: These models know a lot about everything, but nothing about you.
They can answer general questions, draft emails, and summarize the history of jazz, but they don’t know how your company operates, what your customers expect, or how your internal systems are structured. That’s your business’s knowledge. It’s edge. And that’s what they’re missing.
So when I talk to clients about working with foundation models, I often use a simple analogy:
Think of a foundation model like a shrink-wrapped college grad.
They’ve spent years absorbing general knowledge—history, math, language, computer science, maybe even a few philosophy electives. They’re smart. Broadly informed. But they don’t yet know how you do things. They’ve never been inside your business, they don’t know your workflows, and they haven’t lived through your weird industry quirks.
They’re ready to learn. But the quality of that learning depends entirely on how you teach them.
Some of the best-performing companies in the world are known for their onboarding—how they train employees on day one to not just do the job, but to do it their way. With AI, the same principle applies. But instead of crafting training programs, you’re curating datasets. Instead of a week-long orientation, you’re creating repeatable processes that teach the model how to think and respond like someone inside your organization.
The tools are powerful. But they’re blank on the most important stuff: your data, your culture, your expectations.
That’s where integration comes in. That’s where the real work starts.
So now, with that in mind, let’s pause and break down the major ways these foundation models actually consume and interact with your data:
• Fine-Tuning: Adjusting a general model with domain-specific data. It’s powerful, but expensive and slow.
• Prompt Injection: Feeding data into the model at runtime, via a prompt. Quick, flexible, great for prototypes.
• RAG (Retrieval-Augmented Generation): Dynamically pulling in relevant documents or facts to answer a question. This is where a lot of real-world business AI is headed—and where integration becomes make-or-break.
Let’s clarify something right out of the gate: you’re not picking and choosing one method from a menu. You’re using all of them—maybe not all at once, but certainly over time, across use cases, or layered within a single product. Each of these approaches—fine-tuning, prompt injection, and RAG—has its strengths, and more importantly, its purpose. Prompt injection can be a great place to prototype or test assumptions. RAG lets you pull in fresh, contextual data in real time. Fine-tuning adds deeper understanding over time. Each method puts different pressure on your data infrastructure, your team, and your expectations. But they all share one common requirement: accessible, well-governed data.
And that’s the part where most companies start to sweat.
But before we get deep into integration strategies or data lake architectures, we need to rewind a bit because the way we talk about prompting itself is already limiting how we think….
That’s just a slice of the chapter—and a small window into the work ahead.
The AI Evolution isn’t about theory or hype. It’s a real-world guide for leaders who want to build smarter orgs, prep their teams, and actually use AI without the hand-waving.
If this hit home, the full book goes deeper with practical frameworks, strategy shifts, and the patterns I’ve seen across startups, enterprises, and everything in between.
📘 Grab your copy of The AI Evolution here.
⭐️ And if you do leave a review. It means a lot. -
Bye SEO, and Hello AEO
If you caught my recent LinkedIn post, I’ve been sounding the alarm on SEO and search’s fading dominance. Not because it’s irrelevant, but because the game is changing fast.
For years, SEO (Search Engine Optimization) has been the foundation of digital discovery. But we’re entering the age of Google Zero—a world where fewer clicks make it past the search results page. Google’s tools (Maps, embedded widgets, AI Overviews) are now hogging the spotlight. And here’s the latest signal: In April, Apple’s Eddy Cue said that Safari saw its first-ever drop in search queries via the URL bar. That’s huge. Safari is the default browser for iPhones and commands over half of U.S. mobile browser traffic. A dip here means a real shift in how people are asking questions.
I’ve felt it in my habits. I still use Google, but I’ve started using Perplexity, ChatGPT, or Claude to ask my questions. It’s not about keywords anymore, it’s about answers. That brings us to a rising idea: AEO — Answer Engine Optimization.
Just like SEO helped businesses get found by Google, AEO is about getting found by AI. Tools like Perplexity and ChatGPT now crawl the open web to synthesize responses. If your content isn’t surfacing in that layer, you’re invisible to the next generation of search.
It’s not perfect—yet. For something like a recipe, the AI might not cite you at all. But for anything involving a recommendation or purchase decision, it matters a lot.
Take this example: I was recently looking for alternatives to QuickBooks. In the past, I’d Google it and skim through some SEO-packed roundup articles. Now? I start with Perplexity or ChatGPT. Both gave me actual product suggestions, citing sources from review sites, Reddit threads, and open web content. The experience felt more tailored. More direct.

If you sell anything—whether it’s a SaaS product, a service, or a physical item this is the new front door. It’s not just about ranking on Google anymore. It’s about being visible to the large language models that shape what users see when they ask.
So, you’re probably asking. How do you optimize for an answer engine? The truth is, the rules are still emerging. But here’s what we know so far:
• Perplexity leans on Bing. It uses Microsoft’s search infrastructure in the background. So your Bing SEO might matter more than you think.
• Sources are visible. Perplexity shows where it pulled info from—Reddit, Clutch, Bench, review sites, etc. If your product is listed or mentioned there, you’ve got a shot.
• Wikipedia still rules. Most AI models treat it as a trusted source. If your business isn’t listed—or your page is thin—you’re missing an easy credibility signal.But the biggest move you can make?
Start asking AI tools what they know about you.Try it. Ask ChatGPT or Perplexity: “What are the top alternatives to [your product]?” or “What is [your business] known for?” See what surfaces. That answer tells you what the AI thinks is true. And just like with Google, you can shape that reality by shaping the sources it learns from.
This shift won’t happen overnight. But it’s already happening.
Don’t just optimize for search. Optimize for answers. -
Welcome to the Vibe Era
Early in the AI revolution, I sat across a founder pitching a low-code solution that claimed to eliminate the need for developers. I was skeptical, after all, I’d heard this pitch before. As an engineer who’s spent a career building digital products, I figured it was another passing trend.
I was wrong. And worse, I underestimated just how fast this change would come.
Today, we’re in a new era. The skills and careers many of us have spent years refining may no longer be the most valuable thing we bring to the table. Not because they’ve lost value, but because the tools have shifted what’s possible.
We’re in an era where one person, equipped with the right AI stack, can match the output of ten. Vibe coding. Vibe marketing. Vibe product development. Small teams (and sometimes solo operators) are launching polished prototypes, creative campaigns, and full-on businesses fast.
For marketers, the traditional team structure is collapsing.
- Need product photos? Generate them with ChatGPT or Meta Imagine.
- Need a product launch video? Runway or Sora has you covered.
- Need a voiceover? Use ElevenLabs.
- Need custom music? Suno AI.
- Need someone to bounce ideas off of? Make an AI agent that thinks with you.
What used to take a full team now takes… vibes and tools.
The same applies to developers. Tools like Lovable let you spec and ship an MVP in minutes. I recently used it to build a simple app from scratch, and it took me less than an hour. It’s not perfect, but it’s good enough to rethink how we define “development.”
As I often say in my talks, we are still in the AOL dial-up phase of this revolution. This version of AI you’re using today is the worst it will ever be.
Even if you think, “I could write better code” or “that copy isn’t quite there,” remember: these tools get better with every click and every release. Critiquing their limits is fair, but betting against their progress? That’s dangerous.
Shopify’s CEO recently said, “Before hiring someone, I ask: Is this a job AI can do?” That’s not just a hiring philosophy—it’s a survival strategy. It’s catching on fast.
That leads to a deeper question: If AI can handle the tactical and mechanical parts of your work, then what’s left that only you or I can do?
For marketers, it’s the story behind the product.
For developers, it’s solving human problems—not just writing code.
For writers, it’s the reporting, not the sentences.
(Just read The Information’s deep dive on Apple’s AI stumbles—AI could’ve written it, but it couldn’t have reported it.)
This is the heart of the vibe era. It’s not about replacing humans—it’s about refocusing them. On feel. On instinct. On taste.
AI does the repetitive parts. You bring the spark.
In essence, vibe marketing (and vibe everything) is a shift in what matters most: You focus on crafting emotional resonance—the vibe—while AI handles execution.
It’s tailor-made for teams that want to scale fast and connect authentically in a world moving faster than ever.
To borrow a metaphor:
Stephen King isn’t great because of just the words on the page.
He’s great because of the ideas he puts there.
And that’s where the human magic still lives.
-
The Worst It Will Ever Be
One thing I often say in my talks is that this version of AI you’re using today is the worst it will ever be.
It’s not a knock—it’s a reminder. The pace of progress in AI is staggering. Features that were laughably bad just a year or two ago have quietly evolved into shockingly capable tools. Nowhere is this more obvious than with image generation.
Designers used to love dunking on AI-generated images. We’d share screenshots of twisted hands, off-kilter eyes, and text that looked like a keyboard sneezed. And for good reason—it was bad. But release by release, the edges have been smoothed. The hands make sense. The faces feel grounded. And the text? It finally looks like, well, text.
Miyazaki’s Legacy Meets AI
This all came to mind again recently when an old clip of Hayao Miyazaki started circulating. If you’re not familiar, Miyazaki is the legendary co-founder of Studio Ghibli, the anime studio behind Spirited Away, My Neighbor Totoro, and Princess Mononoke. His art style is iconic—whimsical, delicate, and instantly recognizable. Ghibli’s work isn’t just beautiful; it’s emotional. It feels human.
So when Miyazaki was shown an early AI-generated video years ago, his response was brutal:
“I strongly feel that this is an insult to life itself.”
Oof. But here we are in 2025, and now people are using ChatGPT’s new image generation feature to recreate scenes in Studio Ghibli’s style with eerie accuracy.
Of course, I had to try it.

And I have to admit—it’s impressive. Not just the style replication, but the fact that the entire composition gets pulled into that world. The lighting, the mood, the characters… the tool doesn’t just apply a filter. It understands the vibe.
Muppets, Comics, and Infographics, Oh My
Inspired by the experiment, I went down the rabbit hole.
First: Muppets. I blame my older brother James for this idea, but I started generating Muppet versions of our family and a few friends. The results were weirdly good—cheery felt faces, button eyes, and backgrounds that still somehow made sense. It even preserved details from the original photos, just muppet-ified.

The Muppet version of one of my favorite photos – you can see it on my about page. Then I wondered—could this work for layout-driven design? What about infographics?
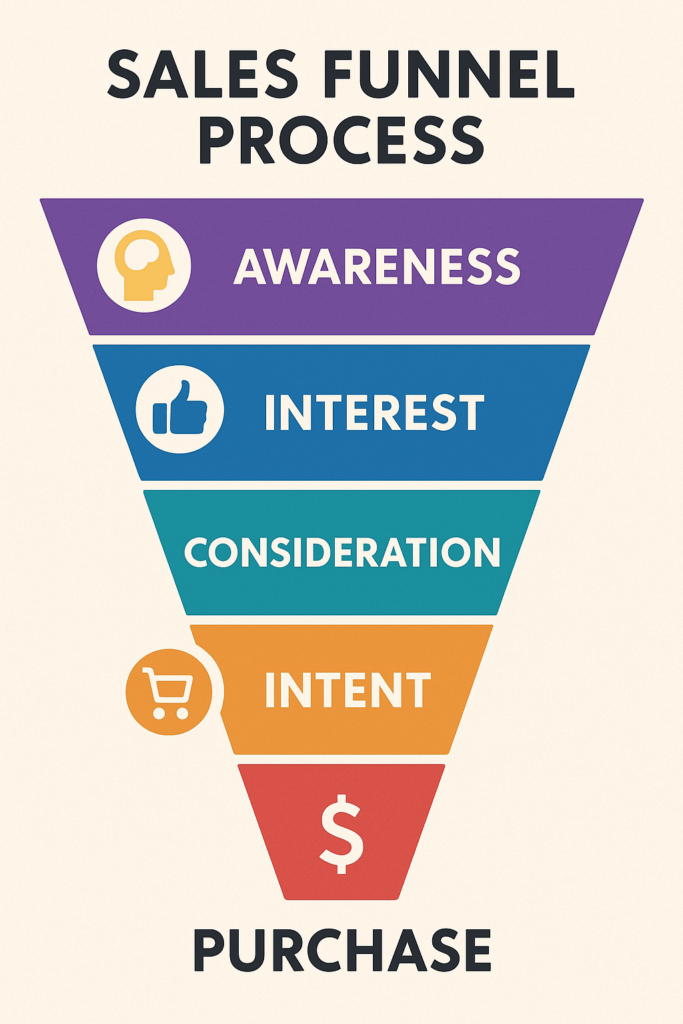
This was the prompt: I need an infographic that shows the sales funnel process I suggest companies use – use this as inspiration Again, it nailed it. The AI could not only generate visuals, but correctly layer and position readable, realistic text onto the images—a feat that was basically impossible in the early days of AI art.
So I pushed further: comics.
Could I recreate the clean simplicity of XKCD or the style of something like the popular The Far side comic strip?

The original XKCD comic is much, much better… 
ChatGPT and I made a version of my favorite Far Side comic…. I hear this is where the brightest minds work From Toy to Tool
You can’t snap your fingers and expect instant results. But it’s no longer just a toy. It’s a creative partner—and if you’re a designer, marketer, or content creator, it’s something you should be exploring now.
And here’s the big takeaway. Even if the images don’t quite reach your final vision, they’re now good enough to prototype, storyboard, or inspire a full design process. The creative bar keeps rising—and so does the floor.
So if you haven’t played with ChatGPT’s image generation yet, try it out. Generate something weird. Make a comic. Turn yourself into a Muppet. Just remember: This is the worst version of the tool you’ll ever use.
-
Rise of the Reasoning Models

Last week, I sat on a panel at the Maryland Technology Council’s Technology Transformation Conference to discuss Data Governance in the Age of AI alongside an incredible group of experts. During the Q&A, someone asked about DeepSeek and how it changes how we think about data usage—a question that speaks to a fundamental shift happening in AI.
When I give talks on AI, I often compare foundation models—AI models trained on vast datasets—to a high school or college graduate entering the workforce. These models are loaded with general knowledge, and just like a college graduate or a master’s degree holder, they may be specialized for particular industries.
If this analogy holds, models like ChatGPT and Claude are strong generalists, but what makes a company special is its secret sauce—the unique knowledge, processes, and experience that businesses invest heavily in teaching their employees. That’s why large proprietary datasets have been key to training AI, ensuring models understand an organization’s way of doing things.
DeepSeek changes this approach. Unlike traditional AI models trained on massive datasets, DeepSeek was built on a much smaller dataset—partly by distilling knowledge from other AI models (essentially asking OpenAI and others questions). Lacking billions of training examples, it had to adapt—which led to a breakthrough in reasoning. Instead of relying solely on preloaded knowledge, DeepSeek used reinforcement learning—a process of quizzing itself, reasoning through problems, and improving iteratively. The result? It became smarter without needing all the data upfront.
If we go back to that college graduate analogy, we’ve all worked with that one person who gets it. Someone who figures things out quickly, even if they don’t have the same background knowledge as others. That’s what’s happening with AI right now.
Over the last few weeks, every major AI company seems to be launching “reasoning models”—possibly following DeepSeek’s blueprint. These models use a process called Chain of Thought (COT), which allows them to analyze problems step by step, effectively “showing their work” as they reason through complex tasks. Think of it like a math teacher asking students to show their work—except now, AI can do the same, giving transparency into its decision-making process.
Don’t get me wrong—data is still insanely valuable. Now, the question is: Can a highly capable reasoning model using Chain of Thought deliver answers as effectively as a model pre-trained on billions of data points?
My guess? Yes.
This changes how companies may train AI models in the future. Instead of building massive proprietary datasets, businesses may be able to pull pre-built reasoning models off the shelf—just like hiring the best intern—and put them to work with far less effort.
-
Writing an AI-Optimized Resume
Earlier this week, Meta began a round of job cuts and has signaled that 2025 will be a tough year. But they’re far from alone—Microsoft, Workday, Sonos, Salesforce, and several other tech companies have also announced layoffs, leaving thousands of professionals searching for new roles.
In the DMV (DC-Maryland-Virginia), the federal government is also facing unprecedented headwinds, with DOGE taking the lead on buyout packages and the shutdown of entire agencies, including USAID.
Like many of you, some of my friends and family were impacted, and one thing I hear over and over again? The job application process has become a nightmare.
Why Job Searching Feels Broken
For many, job hunting now means submitting tons of applications per week, navigating AI-powered screening tools, and attempting to “game” Applicant Tracking Systems (ATS) just to get noticed. If you’ve ever optimized a website for search engines (SEO), you already understand the challenge—your resume now needs to be written for AI just as much as for human reviewers.
As someone who has been a hiring manager, I know why these AI-powered filters exist. Companies receive an overwhelming number of applications, making AI screening tools a necessary first layer of evaluation—but they also mean that perfectly qualified candidates might never make it past the system.
To get past these filters, job seekers need to think like SEO strategists, using resume optimization techniques to increase their chances of reaching an actual hiring manager.
AI Resume Optimization Tips
To level the playing field, resume-scoring tools have been developed to help applicants evaluate their resumes against job descriptions and ATS filters. These tools offer insights such as:
• Include the job title in a prominent header.
• Match listed skills exactly as they appear in the job description.
• Avoid image-heavy or complex formats—ATS systems are bots parsing text, not designers.
• Optimize keyword density to align with job descriptions while keeping it readable.
• Ensure your resume meets the minimum qualifications—AI won’t infer missing experience.
Once you’ve optimized your resume with these strategies, AI-powered tools can help you analyze your resume against job descriptions to see how well it matches and provide targeted improvement suggestions.
Testing AI Resume Scoring with JobScan
To put this into practice, I submitted my resume to Jobscan to see how well it aligned with a Chief Technology Officer (CTO) job posting in Baltimore that I found on ZipRecruiter.

I’ll admit, Jobscan was a bit finicky at first and pushed hard for an upgrade, but once I got my resume and job description uploaded, it generated a report analyzing my match score and offering several helpful suggestions to improve my resume for the job description I provided.

The results provided a rating based on my resume’s content and offered useful insights, including:
- Hard and soft skills are mentioned in the job description and I should add.
- Missing sections or details that could improve my resume’s match.
- Formatting adjustments (like date formats) to improve ATS readability.
It also provided a very detailed report with suggestions to improve the readability, and density of keywords for example, the words “collaboration” and “innovation” were both used 3 times in the job description but the resume mentioned collaboration once, and innovation 6 times.
The tool also offers an option to provide a URL to the job listing it will identify the ATS being used and provide additional suggestions specific to what It knows about that tool.



ChatGPT for Resume Optimization
These days many of us have access to a free or paid version of AI tools like ChatGPT or Claude, so I decided to create a prompt and see how well it could help me. I crafted a prompt that spoke to my needs and provided it with the same resume and job description. For reference here is the prompt I used:
I need to optimize my resume for an AI-powered Applicant Tracking System (ATS) to improve my chances of passing the initial screening process. Below is the job description for the role I’m applying for, followed by my current resume.
Please analyze my resume against the job description and provide the following:
1. A match score or summary of how well my resume aligns with the job description.
2. Key skills, keywords, or qualifications from the job posting that are missing or need to be emphasized.
3. Suggestions for improving formatting and structure to ensure compatibility with ATS filters.
4. Any red flags or areas where my resume could be better tailored to the role.
Jobscan rated my resume at 49%, pointing out missing skills, formatting issues, and keyword gaps. On the other hand, ChatGPT, rated it between 80-85%, focusing more on content alignment rather than rigid formatting rules. However, it had great suggestions and naturally picked up on skills missing in my resume that exist in the job description.
While the ranking was different the recommendations and things ChatGPT pointed out are similar to the results of JobScan just not laid out as simply in a dashboard. This final recommendations section gives a pretty good overview of ChatGPT’s recommendations.

Beating the ATS Game
Most resumes now pass through an ATS before reaching a human hiring manager. Understanding how to optimize for these filters is critical in a competitive job market.
In conclusion, AI and resume-scanning tools have the potential to level the playing field for job seekers—provided they know how to leverage them effectively. And if traditional methods fall short, why not turn the tables? Use AI to go on the offensive, automating your job applications and maximizing your opportunities. Tools like Lazy Apply let AI handle the applications for you, so you can focus on landing the right role.
-
Maps Are Much More Than a Pretty Picture
It’s easy to forget just how decisive and contentious the topic of maps can be. I’m reminded of The West Wing, Season 2, Episode 16, which perfectly captured how something we often take as fact can quickly turn on its head. If you haven’t seen it, watch this snippet—I’ll wait:
This episode came to mind recently with the executive order to rename the Gulf of Mexico and reinstate the name Mount McKinley. Changes like these, once official, ripple beyond their immediate announcements. Today’s maps aren’t just printed in atlases or books—they live on our phones, computers, cars, and apps. Companies with map platforms like Google and Apple, follow international, federal, state and local government sources to define place names and borders. Unsurprisingly, Google has already announced it will update its maps to reflect these changes, and Apple will likely follow.
If this feels like uncharted territory (pun intended), it’s not. After Russia’s annexation of Crimea, many mapping companies faced pressure to update their maps to reflect Crimea as part of Russia. Apple, initially displayed Crimea as part of Ukraine globally, updating its maps to show Crimea as part of Russia—but only for users in Russia.
China has also long lobbied for maps to reflect Taiwan as part of China, sparking ongoing debates about how maps represent geopolitical realities. Even closer to home, cultural shifts are reflected in maps, like when New Orleans renamed Robert E. Lee Blvd to Allen Toussaint Blvd.
Maps are not just representations of geography—they are mirrors of history, politics, and culture. Maps are not just a picture of a territory, they have immense power in shaping how we perceive the world around us.
Update 1/29/2025: Google Maps follows the Geographic Names Information System (GNIS), and under normal circumstances, changes like these would be routine and go unnoticed. However, given the divisiveness of recent name changes, this process has sparked broader debate. It’s likely that Apple and other mapping platforms follow a similar process.
Google has also reclassified the U.S. as a “sensitive country”, adding it to a list that includes China, Russia, Israel, Saudi Arabia, and Iraq. This designation applies to countries with disputed borders or contested place names, similar to Apple’s handling of Crimea.
Update 2/1/2025: John Gruber shared an interesting post on how OpenStreetMap is handling the Gulf of America name change. As a collaborative, community-driven platform, OpenStreetMap has sparked debate on its forums over how to reflect such changes, particularly when they intersect with political decisions. You can follow the community discussion here, where contributors weigh the balance between neutrality and adhering to local or government designations.
-
I Read the DeepSeek Docs So You Don’t Have To
DeepSeek is turning heads in the AI world with two major innovations that flip the usual script for building AI models. Here’s the gist:
Skipping the Study Phase (Supervised Fine-Tuning)
When you train an AI model, the usual first step is something called Supervised Fine-Tuning (SFT). Think of it like studying for a test: you review labeled or annotated data (basically, answers with explanations) to help the model understand the material. After that, the model takes a “quiz” using Reinforcement Learning (RL) to see how much it’s learned.
DeepSeek figured out they could skip most of the study phase. Instead of feeding the model labeled data, they jumped straight to quizzing it over and over with RL. Surprisingly, the model didn’t just keep up—it got better. Without being spoon-fed, it had to “think harder” and reason through questions using the information it already knew.
The “think harder” part is key. Instead of relying on labeled data to tell it what the answers should be, DeepSeek designed a model that had to reason its way to the answers, making it much better at thinking.
This approach relied on a smaller initial dataset for fine-tuning, using only a minimal amount of labeled data to “cold start” the process. As the model answered quizzes during RL, it also generated a “chain of thought,” or reasoning steps, to explain how it arrived at its answers. With continuous cycles of reinforcement learning, the model became smarter and more accurate—faster than with traditional approaches.
By minimizing reliance on SFT, DeepSeek drastically reduced training time and costs while achieving better results.
Mixture of Experts (MoE)
Instead of relying on one big AI brain to do everything, DeepSeek created “experts” for different topics. Think of it like having a math professor for equations, a historian for ancient facts, and a scientist for climate data.
When DeepSeek trains or answers a question, it only activates the “experts” relevant to the task. This saves a ton of computing power because it’s not using all the brainpower all the time—just what’s needed.
This idea, called Mixture of Experts (MoE), makes DeepSeek much more efficient while keeping its responses just as smart.
What Does It Mean?
Using these methods, DeepSeek built an open-source AI model that reasons just as well as OpenAI’s $200/month product—but at a fraction of the cost.
Now, “fraction of the cost” still means millions of dollars and some heavy compute resources, but this is a big deal. DeepSeek has even shared much of their methodology and their models on Hugging Face, making it accessible for others to explore and build upon.
I’m still digging into what makes DeepSeek tick and experimenting with what it can do. As I learn more, I’ll share updates—so be sure to subscribe to the newsletter to stay in the loop!
Footnote: Further Reading
For those curious to dive deeper into the technical details of DeepSeek’s innovations, here are some resources I found useful:
- DeepSeek R1: Reinforcement Learning in Action – VentureBeat’s take on how DeepSeek is challenging AI norms.
- Mixture of Experts and AI Efficiency – A Medium article breaking down the MoE approach.
- Meta Scrambles After DeepSeek’s Breakthrough – An overview of how DeepSeek’s advancements have shaken competitors like Meta.
- DeepSeek R1 Technical Paper – The official documentation for DeepSeek’s R1 model, detailing its innovations.
-
🧠 DeepSeek is redefining the AI race
The juxtaposition of OpenAI and DeepSeek is striking. OpenAI recently announced a deal worth up to $500 billion to build the compute infrastructure required for the next generation of AI models. Meanwhile, DeepSeek, based in China, has developed a competitive AI model on the cheap with a ban that limits their access to the latest and greatest GPUs from Nvidia GPUs.
This contrast is a wake-up call. Meta is reportedly scrambling to understand how DeepSeek managed to achieve this feat, which could upend the competitive landscape in AI development, and OpenAI launched Operator a $200 a month product while DeepSeek is free and open source.
For investors, these developments raise critical questions: Are AI companies overvalued, or does this level of innovation suggest a faster-than-expected path to commoditization for large language models (LLMs)? The race to define the future of AI is accelerating, and the stakes couldn’t be higher.
 DeepSeek R1’s bold bet on reinforcement learning: How it outpaced OpenAI at 3% of the costDeepSeek R1’s Monday release has sent shockwaves through the AI community, disrupting assumptions about what’s required to achieve cutting-edge AI performance. This story focuses on exactly how DeepSeek managed this feat, and what it means for the vast number of users of AI models. For enterprises developing AI-driven solutions, DeepSeek’s breakthrough challenges assumptions of OpenAI’s dominance — and offers a blueprint for cost-efficient innovation.
DeepSeek R1’s bold bet on reinforcement learning: How it outpaced OpenAI at 3% of the costDeepSeek R1’s Monday release has sent shockwaves through the AI community, disrupting assumptions about what’s required to achieve cutting-edge AI performance. This story focuses on exactly how DeepSeek managed this feat, and what it means for the vast number of users of AI models. For enterprises developing AI-driven solutions, DeepSeek’s breakthrough challenges assumptions of OpenAI’s dominance — and offers a blueprint for cost-efficient innovation. -
🧠 You’re Not (actually) Following Trump or Vance…
During the Obama presidency, a key question arose: What happens to a president’s social media followers when they leave office? As the first “social media president,” Obama implemented a solution—creating official accounts like @POTUS and @VP that transition with each administration to maintain continuity in communication.
This week, those same accounts shifted from Biden and Harris to the new administration. So, if you woke up wondering why your feed now features Trump or Vance, here’s your reminder: official accounts follow the office, not the individual. If you want to keep up with the person, make sure to follow their personal or campaign accounts instead.
And no, Facebook isn’t forcing you to follow Trump. If you saw him in your feed, it’s likely because you were already following the official accounts tied to the White House.

