
Category: Uncategorized
-
Savings Unlock Calculator
The Savings Unlock Calculator looks at AI through a different lens: time, efficiency, and “salary not spent.” It shows how much capacity your team can unlock without adding headcount by freeing up FTEs, saving hours, and raising efficiency. The point isn’t just cost-cutting, it’s about finding new room to grow with the team you already have. Try it out!
-
Growth Unlock Calculator
I built this Growth Unlock Calculator to test how AI-driven productivity gains could flow directly into top-line revenue. By plugging in team size, average revenue per employee, and adoption rates, you can see how different impact levels translate into potential growth. Try it out!
-
What the Heck Is MCP?
AI models are built on data. All that data, meticulously scraped and refined, fuels their capacity to handle a staggering spectrum of questions. But as many of you know, their knowledge is locked to the moment they were trained. ChatGPT 3.5, for instance, was famously unaware of the pandemic. Not because it was dumb, but because it wasn’t trained on anything post-2021.
That limitation hasn’t disappeared. Even the newest models don’t magically know what happened yesterday, unless they’re connected to live data. And that’s where techniques like RAG (Retrieval-Augmented Generation) come in. RAG allows an AI to pause mid-response, reach out to external sources like today’s weather report or last night’s playoff score, and bring that data back into the conversation. It’s like giving the model a search engine it can use on the fly.
But RAG has limits. It’s focused on data capture, not doing things. It can help you find an answer, but it can’t carry out a task. And its usefulness is gated by whatever systems your team has wired up behind the scenes. If there’s no integration, there’s no retrieval. It’s useful, but it’s not agentic.
Enter MCP
MCP stands for Model Context Protocol, and it’s an open protocol developed by Anthropic, the team behind Claude. It’s not yet the de facto standard, but it’s gaining real momentum. Microsoft and Google are all in, and OpenAI seems on board. Anthropic hopes that MCP could become the “USB-C” of AI agents, a universal interface for how models connect to tools, data, and services.
What makes MCP powerful isn’t just that it can fetch information. It’s that it can also perform actions. Think of it like this: RAG might retrieve the name of a file. MCP can open that file, edit it, and return a modified version, all without you lifting a finger.
It’s also stateful, meaning it can remember context across multiple requests. For developers, this solves a long-standing web problem. Traditional web requests are like goldfish; they forget everything after each interaction. Web apps have spent years duct-taping state management around that limitation. But MCP is designed to remember. It lets an AI agent maintain a thread of interaction, which means it can build on past knowledge, respond more intelligently, and chain tasks together with nuance.
At Microsoft Build, one demo showed an AI agent using MCP to remove a background from an image. The agent didn’t just describe how to do it or explain how a user might remove a background; it called Microsoft Paint, passed in the image, triggered the action, and received back a new file with the background removed.
MCP enables agents to access the headless interfaces of applications, with platforms like Figma and Slack now exposing their functionality through standardized MCP servers. So, instead of relying on fragile screen-scraping or rigid APIs, agents can now dynamically discover available tools, interpret their functions, and use them in real time.
That’s the holy grail for agentic AI: tools that are discoverable, executable, and composable. You’re not just talking to a chatbot. You’re building a workforce of autonomous agents capable of navigating complex workflows with minimal oversight.
Imagine asking an agent to let a friend know you’re running late – with MCP, the agent can identify apps like email or WhatsApp that support the protocol, and communicate with them directly to get the job done. More complex examples could involve an agent creating design assets in an application such as Figma and then exporting assets into a developer application like Visual Studio Code to implement a website. The possibilities are endless.
The other win? Security. MCP includes built-in authentication and access control. That means you can decide who gets to use what, and under what conditions. Unlike custom tool integrations or API gateways, MCP is designed with enterprise-grade safeguards from the start. That makes it viable not just for tinkerers but for businesses that need guardrails, audit logs, and role-based permissions.
Right now, most MCP interfaces run locally. That’s partly by design; local agents can interact with desktop tools in ways cloud models can’t. But we’re already seeing movement toward the web. Microsoft is embedding MCP deeper into Windows, and other companies are exploring ways to expose cloud services using the same model. If you’ve built RPA (Robotic Process Automation) systems before, this is like giving your bots superpowers and letting them coordinate with AI agents that actually understand what they’re doing.
If you download Claude Desktop and have a paid Anthropic account, you can start experimenting with MCP right now. Many developers have shared example projects that talk to apps like Slack, Notion, and Figma. As long as an application exposes an MCP server, your agent can query it, automate tasks, and chain actions together with ease.
At PerryLabs, we’re going a step further. We’re building custom MCP servers that connect to a company’s ERP or internal APIs, so agents can pull live deal data from HubSpot, update notes and tasks from a conversation, or generate a report and submit it through your business’s proprietary platform. It’s not just automation. It’s intelligent orchestration across systems that weren’t designed to talk to each other.
What’s wild is that this won’t always require a prompt or a conversation. Agentic AI means the agent just knows what to do next. You won’t ask it to resize 10,000 images—it will do that on its own. You’ll get the final folder back, with backgrounds removed, perfectly cropped, and brand elements adjusted—things we once assumed only humans could handle.
MCP makes that future real. As the protocol matures, the power of agentic AI will only grow.
If you’re interested in testing out how MCP can help you build smarter agents or want to start embedding MCP layers into your applications, reach out. We’d love to show you what’s possible.
-
A Week of Dueling AI Keynotes
Microsoft Build. Google I/O. One week, two keynotes, and a surprise plot twist from OpenAI. I flew to Seattle for Build, but the week quickly became about something bigger than just tool demos; it was a moment that clarified how fast the landscape is moving and how much is on the line.
For Microsoft, the mood behind the scenes is… complicated. Their internal AI division hasn’t had the impact some expected. And the OpenAI partnership—the crown jewel of their AI strategy—feels increasingly uneasy. OpenAI has gone from sidekick to wildcard. Faster releases, bolder moves, and a growing sense that Microsoft is no longer in the driver’s seat.
Google has its own tension. It still prints money through ads, but it just lost two major antitrust cases and is deep in the remedies stage, which could change the company forever. Meanwhile, the company is trying to reinvent itself around AI, even at its core business model (search + ads) starts to look shaky in a world where answers come from chat, not clicks.
Let’s start with Microsoft
The Build keynote focused squarely on developers and, more specifically, how AI can make them exponentially more powerful. This idea—AI as a multiplier for small, agile teams—is core to how I think about Vibe Teams. It’s not about replacing engineers. It’s about amplifying them. And this year, Microsoft leaned in hard.
One of the most exciting announcements was GitHub Copilot Agents. If you’ve played with tools like Claude Code or Lovable, you know how quickly AI is changing the way we write software. We’re moving from line-by-line coding to spec-driven development, where you define what the system should do, and agentic AI figures out how.
Copilot Agents takes that further. You can now assign an issue or bug ticket in GitHub to an AI agent. That agent will create a new branch, tackle the task, and submit a pull request when it’s done. You review the PR, suggest edits if needed, and decide whether to merge. No risk to your main codebase. No rogue commits. Just a smart collaborator who knows the rules of the repo.
This isn’t just task automation—it’s the blueprint for how teams might work moving forward. Imagine a lead engineer writing specs and reviewing pull requests—not typing out every line of code but conducting an orchestra of agentic contributors. These agents aren’t sidekicks. They’re teammates. And they don’t need coffee breaks.
Sam Altman joined Satya Nadella remotely – another telling sign that their relationship is collaborative but increasingly arms-length. Satya reiterated Microsoft’s long view, and Sam echoed something I’ve said for a while now: “Today’s AI is the worst AI you’ll ever use.” That’s both a promise and a warning.
The next wave of announcements went deeper into the Microsoft stack. Copilot is being deeply embedded into Microsoft 365, supported by a new set of Copilot APIs and an Agent Toolkit. The goal? Create a marketplace of plug-and-play tools that expand what Copilot Studio agents can access. It’s not just about making Teams smarter – it’s about turning every Microsoft app into an environment agents can operate inside and build upon.
Microsoft also announced Copilot Tuning inside Copilot Studio – a major upgrade that lets companies bring in their own data, refine agent behavior, and customize AI tools for specific use cases. But the catch? These benefits are mostly for companies that are all-in on Microsoft. If your team uses Google Workspace or a bunch of best-in-breed tools, the ecosystem friction shows.
Azure AI Studio is also broadening its model support. While OpenAI remains the centerpiece, Microsoft is hedging its bets. They’re now adding support for LLaMA, HuggingFace, GrokX, and more. Azure is being positioned as the neutral ground—a place where you can bring your model and plug it into the Microsoft stack.
Now for the real standout: MCP.
The Model Context Protocol—originally developed by Anthropic—is the breakout standard of the year. It’s like USB-C for AI. A simple, universal way for agents to talk to tools, APIs, and even hardware. Microsoft is embedding MCP into Windows itself, turning the OS into an agent-aware system. Any app that registers with the Windows MCP registry becomes discoverable. An agent can see what’s installed, what actions are possible, and trigger tasks, from launching a design in Figma to removing a background in Paint.
This is more than RPA 2.0. It’s infrastructure for agentic computing.
Microsoft also showed how this works with local development. With tools like Ollama and Windows Foundry, you can run local models, expose them to actions using MCP, and allow agents to reason in real-time. It’s a huge shift—one that positions Windows as an ideal foundation for building agentic applications for business.
The implication is clear: Microsoft wants to be the default environment for agent-enabled workflows. Not by owning every model, but by owning the operating system they live inside.
Build 2025 made one thing obvious: vibe coding is here to stay. And Microsoft is betting on developers, not just to keep pace with AI, but to define what working with AI looks like next.
Now Google
Where Build was developer-focused, Google I/O spoke to many audiences, sometimes pitching directly to end-users and sometimes to developers. Google I/O pushed to give a peek at what an AI-powered future could look like inside the Google ecosystem. It was a broader, flashier stage, but still packed with signals about where they’re headed.
The show opened with cinematic flair: a vignette generated entirely by Flow, the new AI-powered video tool built on top of Veo 3. But this wasn’t just a demo of visual generation. Flow pairs Veo 3’s video modeling with native audio capabilities, meaning it can generate voiceovers, sound effects, and ambient noise, all with AI. And more importantly, it understands film language. Want a dolly zoom? A smash cut? A wide establishing shot with emotional music? If you can say it, Flow can probably generate it.
But Google’s bigger focus was context and utility.
Gemini 2.5 was the headliner, a major upgrade to Google’s flagship model, now positioned as their most advanced to date. This version is multimodal, supports longer context windows, and powers the majority of what was shown across demos and product launches. Google made it clear: Gemini 2.5 isn’t just powering experiments—it’s now the model behind Gmail, Docs, Calendar, Drive, and Android.
Gemini 2.5 and the new Google AI Studio offer a powerful development stack that rivals GitHub Copilot and Lovable. Developers can use prompts, code, and multi-modal inputs to build apps, with native support for MCP, enabling seamless interactions with third-party tools and services. This makes AI Studio a serious contender for building real-world, agentic software inside the Google ecosystem.
Google confirmed full MCP support in the Gemini SDK, aligning with Microsoft’s adoption and accelerating momentum behind the protocol. With both tech giants backing it, MCP is well on its way to becoming the USB-C of the agentic era.
And then there’s search.
Google is quietly testing an AI-first search experience that looks a lot like Perplexity – summarized answers, contextual follow-ups, and real-time data. But it’s not the default yet. That hesitation is telling: Google still makes most of its revenue from traditional search-based ads. They’re dipping their toes into disruption while trying not to tip the boat. That said, their advantage—access to deep, real-time data from Maps, Shopping, Flights, and more—is hard to match.
Project Astra offered one of the most compelling demos of the week. It’s Google’s vision for what an AI assistant can truly become – voice-native, video-aware, memory-enabled. In the clip, an agent helps someone repair a bike, look up receipts in Gmail, make phone calls unassisted to check inventory at a store, reads instructions from PDFs, and even pauses naturally when interrupted. Was it real? Hard to say. But Google claims the same underlying tech will power upcoming features in Android and Gemini apps. Their goal is to graduate features from Astra as they evolve from showcase to shippable, moving beyond demos into the day-to-day.
Gemini Robotics hinted at what’s next, training AI to understand physical environments, manipulate objects, and act in the real world. It’s early, but it’s a step toward embodied robotic agents.
And then came Google’s XR glasses.
Not just the long-rumored VR headset with Samsung, but a surprise reveal: lightweight glasses built with Warby Parker. These aren’t just a reboot of Google Glass. They feature a heads-up display, live translation, and deep Gemini integration. That display can able to silently serve up directions, messages, or contextual cues, pushing them beyond Meta’s Ray-Bans, which remain audio-only. These are ambient, spatial, and persistent. You wear them, and the assistant moves with you.
Between Apple’s Vision Pro, Meta’s Orion prototypes, and now Google XR, one thing is clear: we’re heading into a post-keyboard world. The next interface isn’t a screen, it’s an environment. And Google’s betting that Gemini, which they say now leads the field in model performance, will be the AI to power it all.
And XR glasses seem like a perfect time for Sam Altman to steal the show…
OpenAI and IO sitting in a tree…
Just as Microsoft and Google finished their keynotes, Sam Altman and Jony Ive dropped the week’s final curveball: OpenAI has acquired Ive’s AI hardware-focused startup, IO, for a reported $6.5 billion.
There were no specs, no images, and no product name. Just a vision. Altman said he took home a prototype, and it was enough to convince him this was the next step. ‘I’ve described the device as something designed to “fix the faults of the iPhone,” less screen time, more ambient interaction. Rumors suggest it’s screenless, portable, and part of a family of devices built around voice, presence, and smart coordination.
In a week filled with agents, protocols, and assistant upgrades, the IO announcement begs the question:
What is the future of computing? Are Apple, Google, Meta, and so many other companies right to bet on glasses?
And if it’s not glasses, not headsets, not wearables, we’ve already seen—but something entirely new. What might the new interface to computing look like?
And with Ive on board, design won’t be an afterthought. This won’t be a dev kit in a clamshell. It’ll be beautiful. Personal. Probably weird in all the right ways.
So where does that leave us?
AI isn’t just getting smarter—it’s getting physical.
Agents are learning to talk to software through MCP. Assistants are learning your context across calendars, emails, and docs. Models are learning to see and act in the world around them. And now hardware is joining the party.
We’re entering an era where the tools won’t just be on your desktop—they’ll surround you. Support you. Sometimes, speak before you do. That’s exciting. It’s also unsettling. Because as much as this future feels inevitable, it’s still up for grabs.
The question isn’t whether agentic AI is coming. It’s who you’ll trust to build the agent that stands beside you.
Next up: WWDC on June 10. Apple has some catching up to do. And then re:Invent later this year.
-
The AI Evolution: Approaching Data and Integration
“I’ve seen things you people wouldn’t believe.”
– Roy Batty, Blade RunnerWorking in consulting gives you a kind of X-ray vision. You walk into a room with a new client and they start listing all the reasons they’re unique—how no one understands their business, how their systems are one-of-a-kind, how the complexity of what they do defies replication. And sure, some of that is true. Every organization has things that make it unique and its oddities. But once you get past the surface, you usually find something that feels familiar: a recognizable business structure layered with years of adaptations, workarounds, and mismatched systems that were never quite built to talk to each other.
When it comes to AI, this same story plays out over and over again. We start talking about the opportunities—where it could go, what it might unlock—and then we hit the same wall: the data. Or more accurately, the data they think they have.
Here are some common refrains I’ve heard across industries:
• “Those two systems don’t talk to each other.”
• “That data is stored in PDFs we print and file away.”
• “We purge that information every few months because of compliance.”
• “It’s in SharePoint. Somewhere. Maybe.”
• “Our marketing and sales platforms use different ID systems, so we can’t link anything.”
None of these answers are surprising. What’s surprising is how often people are still shocked when their AI project struggles to get off the ground.
In our survey, 44% of business leaders said that their companies are planning to implement data modernization efforts in 2024 to take better advantage of Gen AI.
PWC 2024 AI Business Predictions
This chapter is about getting real about your data. Before you can build intelligent systems, you have to integrate them. And before you can integrate them, you have to understand what data you have, where it lives, what shape it’s in, and whether it’s even useful in the first place.
Most companies assume their data is more usable than it actually is, which creates the Illusion of Readiness.
They picture their systems like neat rows of filing cabinets, all labeled and accessible. The reality is more like a junk drawer: some useful stuff, some random receipts, and a bunch of keys no one remembers the purpose of.
And here’s the kicker: AI doesn’t just use data. It relies on it. Feeds off it. Becomes it. If you give it bad data, it doesn’t know any better. It won’t tell you it’s confused. It will confidently give you the wrong answer—and that can have consequences.
Before we get into the mechanics of how AI consumes data, we need to talk about what kind of AI we’re actually working with.
The term you’ll hear a lot is foundation model.
These are large, general-purpose AI models trained on vast swaths of data—think billions upon billions of pieces of information. They’ve read the internet. Absorbed the classics. Ingested code repositories, encyclopedias, manuals, blogs, customer reviews, Reddit threads, medical journals, and everything in between. Foundation models like ChatGPT, Claude, Gemini, and Llama are built by major AI labs with enormous compute budgets and access to vast training sets. The result? Models with broad, flexible knowledge and the ability to respond to all sorts of queries, even ones they’ve never explicitly seen before.
To understand how these models work—and how you’ll be charged for them—you need to know about tokens.
A token is a unit of language. It’s not quite a word, and not quite a character. Most AI models split up text into these tokens to process input and generate output. For example, the phrase “foundation models are smart” becomes something like: “foundation,” “models,” “are,” “smart.” Each token costs money to process, both in and out. That means longer prompts, longer documents, and longer replies increase your cost.
But it’s not just about billing. Tokens define the model’s short-term memory, called the context window. Each model has a limited number of tokens it can “see” at any given time. Once you exceed that limit, earlier parts of the conversation start to fall out of memory. This is why long chats start to lose focus—and why prompts or instruction sets, RAG results, and injected context have to be compact and relevant. The more efficient your language, the smarter your AI becomes.
But not every task needs a giant model.
If you’re running a chatbot that answers routine FAQs, sorting support tickets, or parsing form submissions, a smaller and faster model will likely serve you better—and at a much lower cost. Foundation models are impressive, but they’re not always the most efficient tool in the toolbox. The art of modern AI isn’t about grabbing the biggest brain in the room. It’s about choosing the right model for the right job—and knowing when to escalate to something more powerful only when the problem truly demands it.
They’re called “foundation” models for a reason: they serve as the base layer on which other, more specialized AI systems are built.
But here’s the catch: These models know a lot about everything, but nothing about you.
They can answer general questions, draft emails, and summarize the history of jazz, but they don’t know how your company operates, what your customers expect, or how your internal systems are structured. That’s your business’s knowledge. It’s edge. And that’s what they’re missing.
So when I talk to clients about working with foundation models, I often use a simple analogy:
Think of a foundation model like a shrink-wrapped college grad.
They’ve spent years absorbing general knowledge—history, math, language, computer science, maybe even a few philosophy electives. They’re smart. Broadly informed. But they don’t yet know how you do things. They’ve never been inside your business, they don’t know your workflows, and they haven’t lived through your weird industry quirks.
They’re ready to learn. But the quality of that learning depends entirely on how you teach them.
Some of the best-performing companies in the world are known for their onboarding—how they train employees on day one to not just do the job, but to do it their way. With AI, the same principle applies. But instead of crafting training programs, you’re curating datasets. Instead of a week-long orientation, you’re creating repeatable processes that teach the model how to think and respond like someone inside your organization.
The tools are powerful. But they’re blank on the most important stuff: your data, your culture, your expectations.
That’s where integration comes in. That’s where the real work starts.
So now, with that in mind, let’s pause and break down the major ways these foundation models actually consume and interact with your data:
• Fine-Tuning: Adjusting a general model with domain-specific data. It’s powerful, but expensive and slow.
• Prompt Injection: Feeding data into the model at runtime, via a prompt. Quick, flexible, great for prototypes.
• RAG (Retrieval-Augmented Generation): Dynamically pulling in relevant documents or facts to answer a question. This is where a lot of real-world business AI is headed—and where integration becomes make-or-break.
Let’s clarify something right out of the gate: you’re not picking and choosing one method from a menu. You’re using all of them—maybe not all at once, but certainly over time, across use cases, or layered within a single product. Each of these approaches—fine-tuning, prompt injection, and RAG—has its strengths, and more importantly, its purpose. Prompt injection can be a great place to prototype or test assumptions. RAG lets you pull in fresh, contextual data in real time. Fine-tuning adds deeper understanding over time. Each method puts different pressure on your data infrastructure, your team, and your expectations. But they all share one common requirement: accessible, well-governed data.
And that’s the part where most companies start to sweat.
But before we get deep into integration strategies or data lake architectures, we need to rewind a bit because the way we talk about prompting itself is already limiting how we think….
That’s just a slice of the chapter—and a small window into the work ahead.
The AI Evolution isn’t about theory or hype. It’s a real-world guide for leaders who want to build smarter orgs, prep their teams, and actually use AI without the hand-waving.
If this hit home, the full book goes deeper with practical frameworks, strategy shifts, and the patterns I’ve seen across startups, enterprises, and everything in between.
📘 Grab your copy of The AI Evolution here.
⭐️ And if you do leave a review. It means a lot. -
Bye SEO, and Hello AEO
If you caught my recent LinkedIn post, I’ve been sounding the alarm on SEO and search’s fading dominance. Not because it’s irrelevant, but because the game is changing fast.
For years, SEO (Search Engine Optimization) has been the foundation of digital discovery. But we’re entering the age of Google Zero—a world where fewer clicks make it past the search results page. Google’s tools (Maps, embedded widgets, AI Overviews) are now hogging the spotlight. And here’s the latest signal: In April, Apple’s Eddy Cue said that Safari saw its first-ever drop in search queries via the URL bar. That’s huge. Safari is the default browser for iPhones and commands over half of U.S. mobile browser traffic. A dip here means a real shift in how people are asking questions.
I’ve felt it in my habits. I still use Google, but I’ve started using Perplexity, ChatGPT, or Claude to ask my questions. It’s not about keywords anymore, it’s about answers. That brings us to a rising idea: AEO — Answer Engine Optimization.
Just like SEO helped businesses get found by Google, AEO is about getting found by AI. Tools like Perplexity and ChatGPT now crawl the open web to synthesize responses. If your content isn’t surfacing in that layer, you’re invisible to the next generation of search.
It’s not perfect—yet. For something like a recipe, the AI might not cite you at all. But for anything involving a recommendation or purchase decision, it matters a lot.
Take this example: I was recently looking for alternatives to QuickBooks. In the past, I’d Google it and skim through some SEO-packed roundup articles. Now? I start with Perplexity or ChatGPT. Both gave me actual product suggestions, citing sources from review sites, Reddit threads, and open web content. The experience felt more tailored. More direct.

If you sell anything—whether it’s a SaaS product, a service, or a physical item this is the new front door. It’s not just about ranking on Google anymore. It’s about being visible to the large language models that shape what users see when they ask.
So, you’re probably asking. How do you optimize for an answer engine? The truth is, the rules are still emerging. But here’s what we know so far:
• Perplexity leans on Bing. It uses Microsoft’s search infrastructure in the background. So your Bing SEO might matter more than you think.
• Sources are visible. Perplexity shows where it pulled info from—Reddit, Clutch, Bench, review sites, etc. If your product is listed or mentioned there, you’ve got a shot.
• Wikipedia still rules. Most AI models treat it as a trusted source. If your business isn’t listed—or your page is thin—you’re missing an easy credibility signal.But the biggest move you can make?
Start asking AI tools what they know about you.Try it. Ask ChatGPT or Perplexity: “What are the top alternatives to [your product]?” or “What is [your business] known for?” See what surfaces. That answer tells you what the AI thinks is true. And just like with Google, you can shape that reality by shaping the sources it learns from.
This shift won’t happen overnight. But it’s already happening.
Don’t just optimize for search. Optimize for answers. -
Welcome to the Vibe Era
Early in the AI revolution, I sat across a founder pitching a low-code solution that claimed to eliminate the need for developers. I was skeptical, after all, I’d heard this pitch before. As an engineer who’s spent a career building digital products, I figured it was another passing trend.
I was wrong. And worse, I underestimated just how fast this change would come.
Today, we’re in a new era. The skills and careers many of us have spent years refining may no longer be the most valuable thing we bring to the table. Not because they’ve lost value, but because the tools have shifted what’s possible.
We’re in an era where one person, equipped with the right AI stack, can match the output of ten. Vibe coding. Vibe marketing. Vibe product development. Small teams (and sometimes solo operators) are launching polished prototypes, creative campaigns, and full-on businesses fast.
For marketers, the traditional team structure is collapsing.
- Need product photos? Generate them with ChatGPT or Meta Imagine.
- Need a product launch video? Runway or Sora has you covered.
- Need a voiceover? Use ElevenLabs.
- Need custom music? Suno AI.
- Need someone to bounce ideas off of? Make an AI agent that thinks with you.
What used to take a full team now takes… vibes and tools.
The same applies to developers. Tools like Lovable let you spec and ship an MVP in minutes. I recently used it to build a simple app from scratch, and it took me less than an hour. It’s not perfect, but it’s good enough to rethink how we define “development.”
As I often say in my talks, we are still in the AOL dial-up phase of this revolution. This version of AI you’re using today is the worst it will ever be.
Even if you think, “I could write better code” or “that copy isn’t quite there,” remember: these tools get better with every click and every release. Critiquing their limits is fair, but betting against their progress? That’s dangerous.
Shopify’s CEO recently said, “Before hiring someone, I ask: Is this a job AI can do?” That’s not just a hiring philosophy—it’s a survival strategy. It’s catching on fast.
That leads to a deeper question: If AI can handle the tactical and mechanical parts of your work, then what’s left that only you or I can do?
For marketers, it’s the story behind the product.
For developers, it’s solving human problems—not just writing code.
For writers, it’s the reporting, not the sentences.
(Just read The Information’s deep dive on Apple’s AI stumbles—AI could’ve written it, but it couldn’t have reported it.)
This is the heart of the vibe era. It’s not about replacing humans—it’s about refocusing them. On feel. On instinct. On taste.
AI does the repetitive parts. You bring the spark.
In essence, vibe marketing (and vibe everything) is a shift in what matters most: You focus on crafting emotional resonance—the vibe—while AI handles execution.
It’s tailor-made for teams that want to scale fast and connect authentically in a world moving faster than ever.
To borrow a metaphor:
Stephen King isn’t great because of just the words on the page.
He’s great because of the ideas he puts there.
And that’s where the human magic still lives.
-
The Worst It Will Ever Be
One thing I often say in my talks is that this version of AI you’re using today is the worst it will ever be.
It’s not a knock—it’s a reminder. The pace of progress in AI is staggering. Features that were laughably bad just a year or two ago have quietly evolved into shockingly capable tools. Nowhere is this more obvious than with image generation.
Designers used to love dunking on AI-generated images. We’d share screenshots of twisted hands, off-kilter eyes, and text that looked like a keyboard sneezed. And for good reason—it was bad. But release by release, the edges have been smoothed. The hands make sense. The faces feel grounded. And the text? It finally looks like, well, text.
Miyazaki’s Legacy Meets AI
This all came to mind again recently when an old clip of Hayao Miyazaki started circulating. If you’re not familiar, Miyazaki is the legendary co-founder of Studio Ghibli, the anime studio behind Spirited Away, My Neighbor Totoro, and Princess Mononoke. His art style is iconic—whimsical, delicate, and instantly recognizable. Ghibli’s work isn’t just beautiful; it’s emotional. It feels human.
So when Miyazaki was shown an early AI-generated video years ago, his response was brutal:
“I strongly feel that this is an insult to life itself.”
Oof. But here we are in 2025, and now people are using ChatGPT’s new image generation feature to recreate scenes in Studio Ghibli’s style with eerie accuracy.
Of course, I had to try it.

And I have to admit—it’s impressive. Not just the style replication, but the fact that the entire composition gets pulled into that world. The lighting, the mood, the characters… the tool doesn’t just apply a filter. It understands the vibe.
Muppets, Comics, and Infographics, Oh My
Inspired by the experiment, I went down the rabbit hole.
First: Muppets. I blame my older brother James for this idea, but I started generating Muppet versions of our family and a few friends. The results were weirdly good—cheery felt faces, button eyes, and backgrounds that still somehow made sense. It even preserved details from the original photos, just muppet-ified.

The Muppet version of one of my favorite photos – you can see it on my about page. Then I wondered—could this work for layout-driven design? What about infographics?
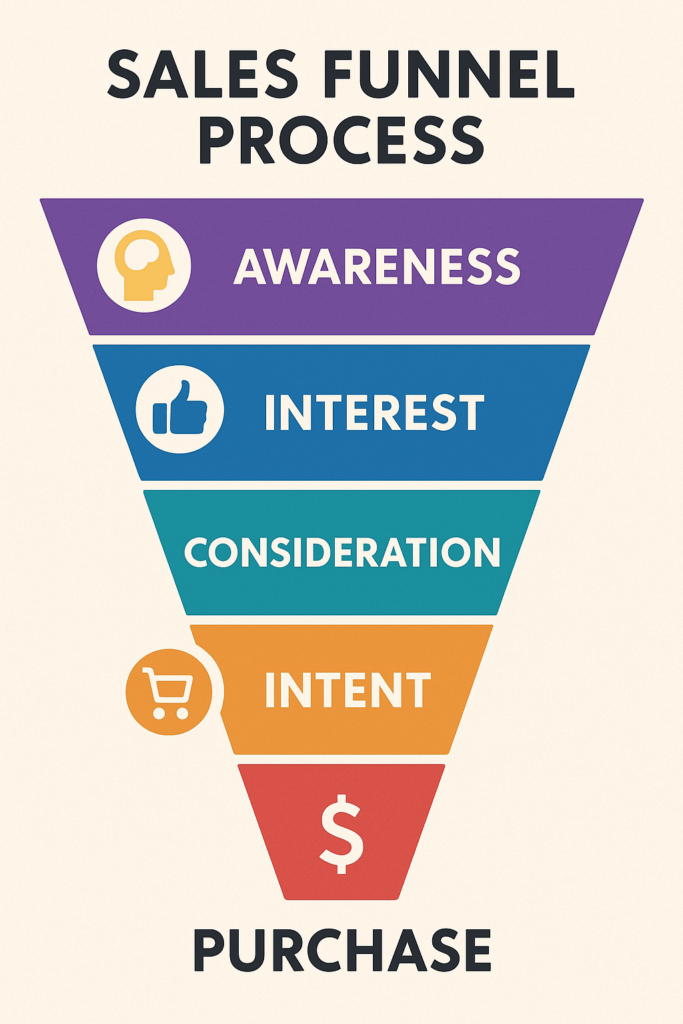
This was the prompt: I need an infographic that shows the sales funnel process I suggest companies use – use this as inspiration Again, it nailed it. The AI could not only generate visuals, but correctly layer and position readable, realistic text onto the images—a feat that was basically impossible in the early days of AI art.
So I pushed further: comics.
Could I recreate the clean simplicity of XKCD or the style of something like the popular The Far side comic strip?

The original XKCD comic is much, much better… 
ChatGPT and I made a version of my favorite Far Side comic…. I hear this is where the brightest minds work From Toy to Tool
You can’t snap your fingers and expect instant results. But it’s no longer just a toy. It’s a creative partner—and if you’re a designer, marketer, or content creator, it’s something you should be exploring now.
And here’s the big takeaway. Even if the images don’t quite reach your final vision, they’re now good enough to prototype, storyboard, or inspire a full design process. The creative bar keeps rising—and so does the floor.
So if you haven’t played with ChatGPT’s image generation yet, try it out. Generate something weird. Make a comic. Turn yourself into a Muppet. Just remember: This is the worst version of the tool you’ll ever use.
-
Rise of the Reasoning Models

Last week, I sat on a panel at the Maryland Technology Council’s Technology Transformation Conference to discuss Data Governance in the Age of AI alongside an incredible group of experts. During the Q&A, someone asked about DeepSeek and how it changes how we think about data usage—a question that speaks to a fundamental shift happening in AI.
When I give talks on AI, I often compare foundation models—AI models trained on vast datasets—to a high school or college graduate entering the workforce. These models are loaded with general knowledge, and just like a college graduate or a master’s degree holder, they may be specialized for particular industries.
If this analogy holds, models like ChatGPT and Claude are strong generalists, but what makes a company special is its secret sauce—the unique knowledge, processes, and experience that businesses invest heavily in teaching their employees. That’s why large proprietary datasets have been key to training AI, ensuring models understand an organization’s way of doing things.
DeepSeek changes this approach. Unlike traditional AI models trained on massive datasets, DeepSeek was built on a much smaller dataset—partly by distilling knowledge from other AI models (essentially asking OpenAI and others questions). Lacking billions of training examples, it had to adapt—which led to a breakthrough in reasoning. Instead of relying solely on preloaded knowledge, DeepSeek used reinforcement learning—a process of quizzing itself, reasoning through problems, and improving iteratively. The result? It became smarter without needing all the data upfront.
If we go back to that college graduate analogy, we’ve all worked with that one person who gets it. Someone who figures things out quickly, even if they don’t have the same background knowledge as others. That’s what’s happening with AI right now.
Over the last few weeks, every major AI company seems to be launching “reasoning models”—possibly following DeepSeek’s blueprint. These models use a process called Chain of Thought (COT), which allows them to analyze problems step by step, effectively “showing their work” as they reason through complex tasks. Think of it like a math teacher asking students to show their work—except now, AI can do the same, giving transparency into its decision-making process.
Don’t get me wrong—data is still insanely valuable. Now, the question is: Can a highly capable reasoning model using Chain of Thought deliver answers as effectively as a model pre-trained on billions of data points?
My guess? Yes.
This changes how companies may train AI models in the future. Instead of building massive proprietary datasets, businesses may be able to pull pre-built reasoning models off the shelf—just like hiring the best intern—and put them to work with far less effort.
-
Writing an AI-Optimized Resume
Earlier this week, Meta began a round of job cuts and has signaled that 2025 will be a tough year. But they’re far from alone—Microsoft, Workday, Sonos, Salesforce, and several other tech companies have also announced layoffs, leaving thousands of professionals searching for new roles.
In the DMV (DC-Maryland-Virginia), the federal government is also facing unprecedented headwinds, with DOGE taking the lead on buyout packages and the shutdown of entire agencies, including USAID.
Like many of you, some of my friends and family were impacted, and one thing I hear over and over again? The job application process has become a nightmare.
Why Job Searching Feels Broken
For many, job hunting now means submitting tons of applications per week, navigating AI-powered screening tools, and attempting to “game” Applicant Tracking Systems (ATS) just to get noticed. If you’ve ever optimized a website for search engines (SEO), you already understand the challenge—your resume now needs to be written for AI just as much as for human reviewers.
As someone who has been a hiring manager, I know why these AI-powered filters exist. Companies receive an overwhelming number of applications, making AI screening tools a necessary first layer of evaluation—but they also mean that perfectly qualified candidates might never make it past the system.
To get past these filters, job seekers need to think like SEO strategists, using resume optimization techniques to increase their chances of reaching an actual hiring manager.
AI Resume Optimization Tips
To level the playing field, resume-scoring tools have been developed to help applicants evaluate their resumes against job descriptions and ATS filters. These tools offer insights such as:
• Include the job title in a prominent header.
• Match listed skills exactly as they appear in the job description.
• Avoid image-heavy or complex formats—ATS systems are bots parsing text, not designers.
• Optimize keyword density to align with job descriptions while keeping it readable.
• Ensure your resume meets the minimum qualifications—AI won’t infer missing experience.
Once you’ve optimized your resume with these strategies, AI-powered tools can help you analyze your resume against job descriptions to see how well it matches and provide targeted improvement suggestions.
Testing AI Resume Scoring with JobScan
To put this into practice, I submitted my resume to Jobscan to see how well it aligned with a Chief Technology Officer (CTO) job posting in Baltimore that I found on ZipRecruiter.

I’ll admit, Jobscan was a bit finicky at first and pushed hard for an upgrade, but once I got my resume and job description uploaded, it generated a report analyzing my match score and offering several helpful suggestions to improve my resume for the job description I provided.

The results provided a rating based on my resume’s content and offered useful insights, including:
- Hard and soft skills are mentioned in the job description and I should add.
- Missing sections or details that could improve my resume’s match.
- Formatting adjustments (like date formats) to improve ATS readability.
It also provided a very detailed report with suggestions to improve the readability, and density of keywords for example, the words “collaboration” and “innovation” were both used 3 times in the job description but the resume mentioned collaboration once, and innovation 6 times.
The tool also offers an option to provide a URL to the job listing it will identify the ATS being used and provide additional suggestions specific to what It knows about that tool.



ChatGPT for Resume Optimization
These days many of us have access to a free or paid version of AI tools like ChatGPT or Claude, so I decided to create a prompt and see how well it could help me. I crafted a prompt that spoke to my needs and provided it with the same resume and job description. For reference here is the prompt I used:
I need to optimize my resume for an AI-powered Applicant Tracking System (ATS) to improve my chances of passing the initial screening process. Below is the job description for the role I’m applying for, followed by my current resume.
Please analyze my resume against the job description and provide the following:
1. A match score or summary of how well my resume aligns with the job description.
2. Key skills, keywords, or qualifications from the job posting that are missing or need to be emphasized.
3. Suggestions for improving formatting and structure to ensure compatibility with ATS filters.
4. Any red flags or areas where my resume could be better tailored to the role.
Jobscan rated my resume at 49%, pointing out missing skills, formatting issues, and keyword gaps. On the other hand, ChatGPT, rated it between 80-85%, focusing more on content alignment rather than rigid formatting rules. However, it had great suggestions and naturally picked up on skills missing in my resume that exist in the job description.
While the ranking was different the recommendations and things ChatGPT pointed out are similar to the results of JobScan just not laid out as simply in a dashboard. This final recommendations section gives a pretty good overview of ChatGPT’s recommendations.

Beating the ATS Game
Most resumes now pass through an ATS before reaching a human hiring manager. Understanding how to optimize for these filters is critical in a competitive job market.
In conclusion, AI and resume-scanning tools have the potential to level the playing field for job seekers—provided they know how to leverage them effectively. And if traditional methods fall short, why not turn the tables? Use AI to go on the offensive, automating your job applications and maximizing your opportunities. Tools like Lazy Apply let AI handle the applications for you, so you can focus on landing the right role.
-
Mindgrub and the Baltimore symphony Orchestra present AI in A Minor

I’m beyond excited to announce AI in A Minor! The Mindgrub team and I have spent the last few months working to generate music and transform it into sheet music the amazing musicians at the BSO can perform. It feels incredible to know that soon you will have a chance to see what we’ve been working on.
I also can’t ask for a better team than the Baltimore Symphony Orchestra, Greater Baltimore Committee, and Amazon Web Services (AWS) to help make this happen.
Join us on August 9th!
Oh, we’re still looking for sponsors and anyone interested in setting up a booth in the BSO hall. If you want to buy tickets get them here!
-
Meta Threads Countdown
It appears 9to5Google got it’s hands onto an early APK release of Meta’s Twitter competitor Threads in “Threads, Meta’s Twitter clone, starts launch countdown, plus a few details on how it works“:
Your Threads profile is also strongly connected to your Instagram profile. The two use the same username and display name, and it seems your Threads profile picture may have to be from Instagram. Additionally, anyone you block on one service is also blocked on the other.
I shouldn’t be surprised by the tight coupling to Instagram, but I am. The coupling between Facebook and Instagram has always felt forced and as if they stifle the personalities of the different platforms. Threads (as I expect it) will be heavily text-focused, while Instagram leans into photos and video. How often will cross-posting happen?
Another unique aspect of Threads that many have been anticipating is the way it can connect to federated social networks like Mastodon (collectively known as the “fediverse”). It seems that Threads may not be ready to launch its fediverse features right away.
Soon, you’ll be able to follow and interact with people on other fediverse platforms, like Mastodon. They can also find you with your full username @username@threads.net.
The only other detail we could uncover about Threads’ integration with the fediverse is that if you choose to restrict replies on a post, it won’t be shared outside of the Threads app.
When you limit replies, your thread will not be shared with your fediverse followers.
Threads’ use of ActivityPub to connect into Mastodon and the collective Fediverse has long been a big question. In my newsletter, I compared Mastodon and the Fediverse to a network of towns, where each city has its form of government and content moderation rules. Threads’ appears to be a gated community that may allow its users to leave the gates and interact with others but still keep exclusive content limited to those within its gates.
This social experiment will be interesting, especially when a metric ton of Meta users who first interact with the larger Fediverse through Threads and branded “@username@threads.net” name. I hope the other cities play nice.
Digging deeper into the code, our team has also found that Threads may indeed have a web app. At the very least, we’ve found that the service’s profile links will look quite similar to Instagram profile links, simply appending your username after the base “threads.net/” URL.
I assumed the animated website for threads hinted at more than just an app.

-
Screen Scraping
Gizmodo has a piece on “Google Says It’ll Scrape Everything you Post Online for AI“:
One of the less obvious complications of the post ChatGPT world is the question of where data-hungry chatbots sourced their information. Companies including Google and OpenAI scraped vast portions of the internet to fuel their robot habits. It’s not at all clear that this is legal, and the next few years will see the courts wrestle with copyright questions that would have seemed like science fiction a few years ago. In the meantime, the phenomenon already affects consumers in some unexpected ways.
Twitter’s crazy rate-limiting meltdown and Reddit’s push to charge for API access are about one thing, AI data models. These systems are hungry for data, and access to that data will be vital to building the best AI models. Unsurprisingly, Google is making it known that as it ranks and offers prime search engine placement, all that delicious data is free game to them. When APIs become closed, people result to screen scrapping, and screen scrapping ends with paywalls and Twitter style rate-limiting… Wonder how this all plays out.