
Issue #33: Training A Smarter AI with the Tokens of Power
Howdy 👋🏾, earlier this year, I launched a little AI playground for testing various models with the same prompt – an experiment allowing head-to-head comparisons evaluating output differences. My AI playground app is still in beta, so pardon any rough edges, but I did take a little time to drop some new additions this weekend:
- Added Perplexity.ai – the latest trendy AI for developers to tap cutting-edge capabilities
- Integrated the hugely multilingual BLOOM model for broader global applications
- Built text-to-speech using quality OpenAI voices
- A parts of speech tool to test tokenization and how natural language processing works
Keep checking back for more updates! I’m running most models on free tiers and token caps, so I apologize if we hit any caps. If you’re interested in sponsoring to cover compute costs and expand the playground, reach out.
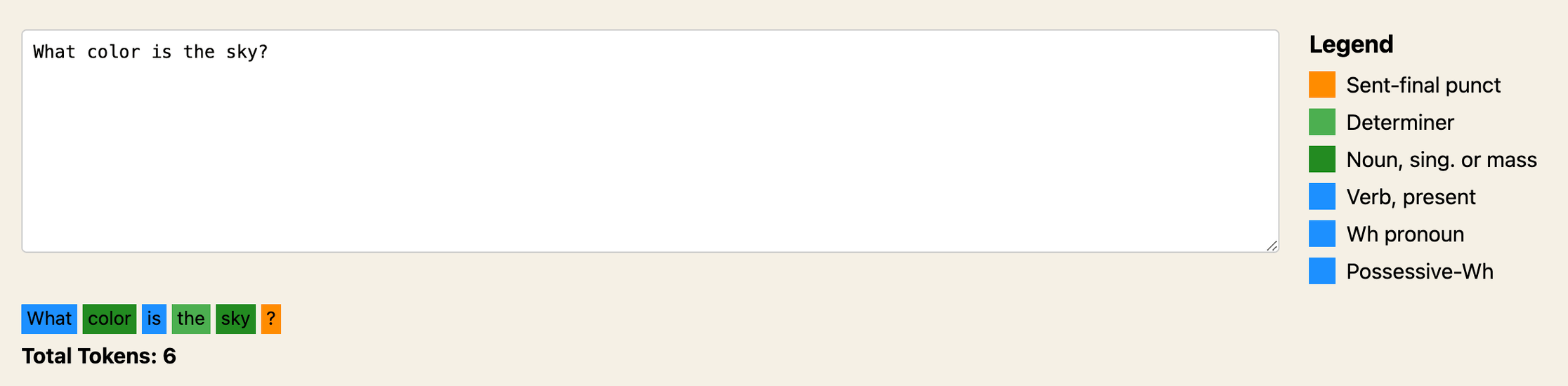
Using any of these models is as simple as typing a prompt, but behind that string lies some interesting complexity. When you submit a text prompt, many AI models first preprocess this with natural language processing or an NLP tool called a tokenizer. A tokenizer splits our phrase into individual words, or “tokens,” allowing isolated examination to discern relationships in the sequence. Take the question – “What color is the sky?”. Tokenizing this yields:{“what”, “color”, “is”, “the”, “sky”}
Creating tokens by word is easy but can require a substantial dictionary in the AI model to understand every possibility. Some tokenizers break up a phrase into subwords or separate modifiers like “eating,” becoming “eat,” and “ing.”
Next, natural language processing identifies part-of-speech and grammatical roles. The NLP tagger labels “sky” as a noun, “color” as a noun, and “the” as a determiner. Understanding role context allows sensible analysis.
These same strings of text we use for our prompts are the same as the structured or unstructured data we use to train AI models. You can imagine developers feeding an AI model content. You might picture a conveyor belt of books, articles, newspapers, and more being dropped into a robot brain a token at a time.
Each of those tokens is used to build a graph that relates words to one another based on how they relate to other words and their usage.
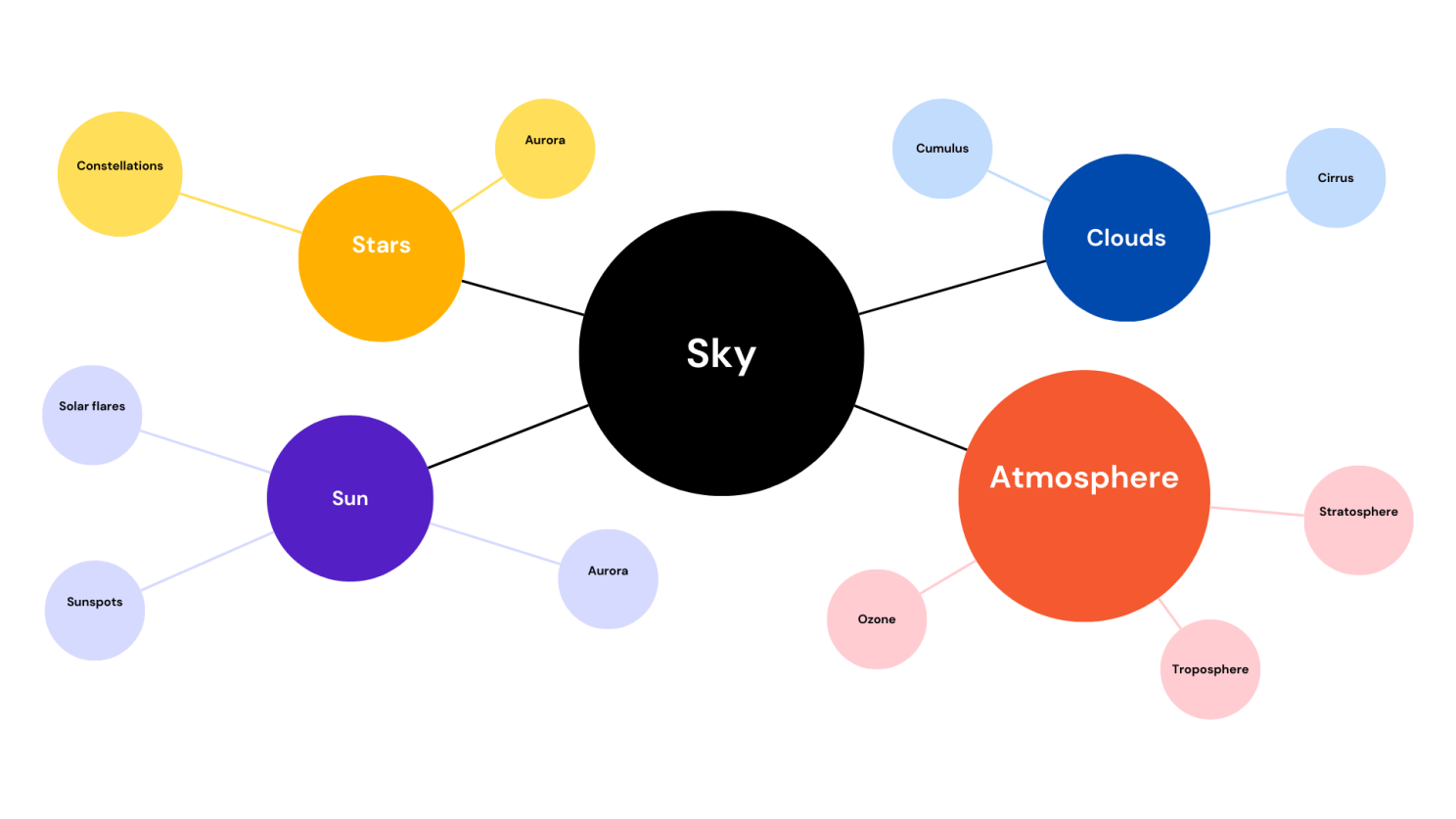
This graph shows words based on the strength of the relationship to a word or the similarity between the words. So for the token “sky,” we might see “atmosphere,” “sun,” “clouds,” and “stars.” This relationship lets us see how a model may infer or understand what something means, and each of these values maintains a weight from +1 to -1 that shows how close a token relates based on the context. Tokens with a negative weight represent opposites like “underground”.
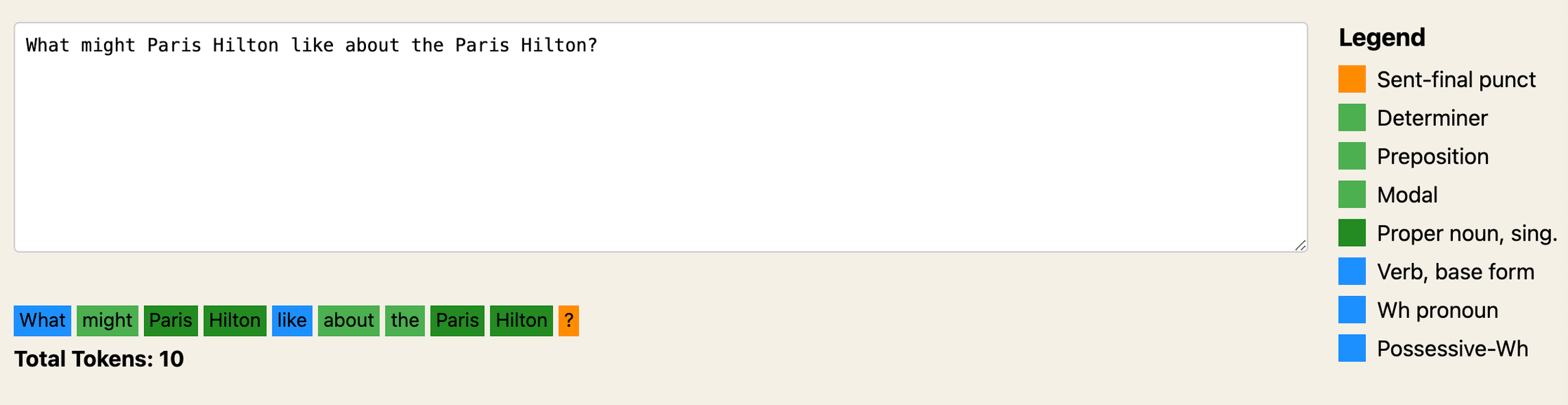
Tokenizers offer valuable insights into an AI model’s text processing. Some may recall the tricky question I posed to various AI models, ‘What might Paris Hilton like about the Paris Hilton?’. The complexity arises as numerous nouns make the part of speech for nouns challenging to decipher, resulting in a complex and confusing graph.
Models also give precedence to the order of tokens. While image generation models, especially those accepting shorter prompts, demonstrate this more evidently, the phrase ‘My favorite fruit is mango slice’ emphasizes my favorite fruit as mango over slices. In contrast, ‘Slices of mango are my favorite fruit’ subtly shifts the focus to slices of mango in interpreting the images.


Text completion prompts often prefer right-to-left emphasis, especially with models that offer large context windows like text-to-text or completion generators. Suppose the left represents the history or the past. Text generators have more and more history from previous messages to the left and assume the right represents newer and fresher content. This allows you to better control the response by focusing on the most important tokens to the end or right of a message. You can discern a model’s preference by observing its reaction to the placement of key information, like a 200-character limit.
For instance, let’s experiment with token emphasis from left to right:
“Compose a 200-word article on the impact of artificial intelligence on healthcare, focusing on the advancements in disease diagnosis and treatment.”
If you test this, many popular LLMs may ignore the word count and focus on the article. Now, let’s shift the emphasis from right to left:
“Compose an article on the impact of artificial intelligence on healthcare, focusing on the advancements in disease diagnosis and treatment in 200 words.”
If you run this in your favorite model, notice how the placement of the 200-character limit influences the model’s response, highlighting the nuanced emphasis based on token positioning.
“Tell me about AI in healthcare.”
Remember, if you overlook these nuances and omit key details, forcing the AI to assume the outcome may not meet expectations. You’re welcome. And now, onto thoughts on Tech & Things:
⚡️ With 180,000 Vision Pro pre-orders but just 150 apps, Apple’s mixed reality play faces developer resistance – but is it deliberate protest or practical reluctance?
⚡️ Mia Sato’s recent piece on the quality of search results and SEO, featured on Marketplace and The Verge, sheds light on the declining quality of search results across platforms like Google. Sato highlights the growing concern that SEO practices contribute to homogenizing web design. The pressure to optimize for search engines may lead to many websites looking remarkably similar.
Large language models use a complex graph of tokens and vector databases to craft responses based on the likelihood of the next word in a sequence. If that sounds like gobbly gop, think of completing the sentence ‘Jack and’ as assembling a puzzle. Adding ‘Jill’ is akin to placing a puzzle piece (token) to construct a meaningful picture (output statement). Our advanced language model settings empower us to fine-tune an obvious answer like “Jill” or embrace variety, whether it’s favorable or not. The untold stories of Jack and Ayanna can be shaped with just a tweak of these properties:
- Temperature: Think of temperature like a cooking flame. Higher temperature (hotter flame) gives you more focused tokens, while lower temperature (cooler flame) introduces more random tokens.
- Top-K: Imagine you have 10 flavors of ice cream, and you pick your top 3 favorites (that’s Top-K = 3). Those 3 are what the shop will choose from to serve you a cone. If you increase Top-K to 5, you allow them to pick from more of your favorites, but the flavor they ultimately grab might not be in your top 3.
- Top-P: Now imagine there are 100 flavors to choose from. Top-P is like asking for a scoop with at least 30% of your favorite flavors (that’s Top-P = 0.3). So, at least 30% of the scoop is bound to be flavors in your top favorites. Make Top-P higher, and you get more of a guarantee that the predominant flavors will be your top preferences. But set it too high (like 90%), and you may end up with less variety.
- Frequency Penalty: It’s like adding more unique spices to a recipe. Frequency Penalty lowers the dominance of common tokens or ingredients, making the dish more diverse.
- Presence Penalty: Consider telling a story. Presence Penalty ensures you don’t repeat the same words too often, making the narrative more engaging.
The newly added Perplexity AI model in the playground invites you to explore these settings across various models. Give it a try and see the creative possibilities unfold!
-jason
p.s. I’m thrilled about finally giving Apple’s Vision Pro a try! We’re actively developing new apps for clients and preparing existing ones for this device. However, I haven’t had the opportunity to experience it firsthand; my interaction has been limited to what I can see in the simulator. Watching this video showcasing the making of the Vision Pro triggered my Apple fanboy excitement! I can’t wait to get my hands on it. If you’re curious how it might work, this video walkthrough is excellent.